引言
代码注释能够提高代码的可读性,在软件开发和维护工作中具有重要意义。代码注释生成任务(Code Comment Generation)是自然语言生成最具挑战性的任务之一。旨在把源代码自动转化为对应的代码注释,从而提高工程开发效率。
现有的研究工作主要基于Encoder-Decoder框架。通过利用编码器对源代码进行编码,得到一个源代码的语义编码表达。然后解码器根据该编码表达解码出代码注释文本。关于源代码的编码,现有工作主要考虑两个方面的信息:1)文本信息,这方面的工作基于源代码文本序列作输入,采取形如Sequence-to-Sequence的模型去处理;2)结构信息,这方面的工作基于源代码的抽象语法树作输入,采取形如Tree-to-Sequence和Graph-to-Sequence的模型去处理。
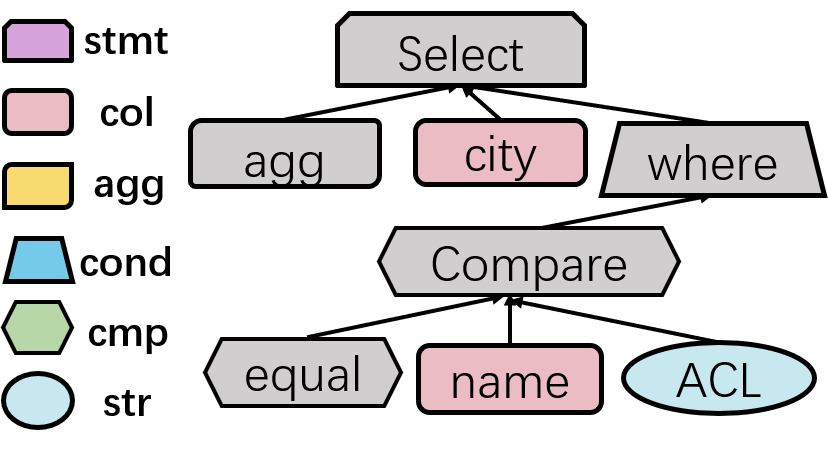
目前抽象语法树是更常用的源代码表示形式。因为它是源代码的抽象表达,能够体现出源代码的结构和文本内容等关键信息。抽象语法树的每个节点除了节点值之外,还含有节点类型。
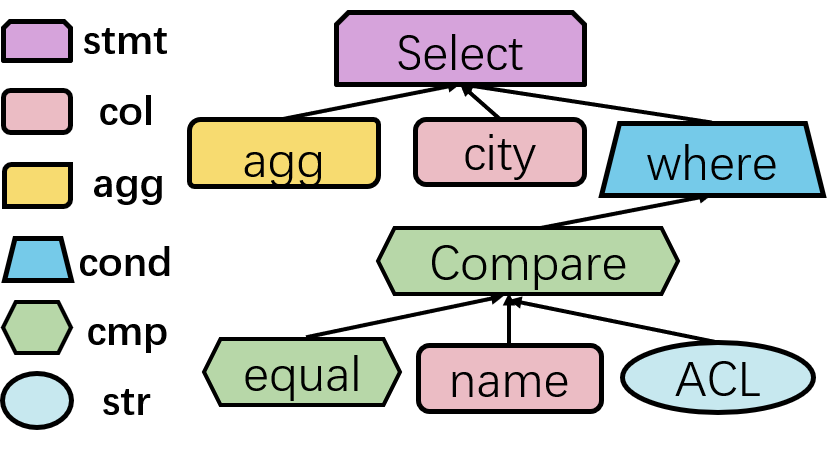
图一 SQL语法树
但是这些工作含有以下不足:1)编码阶段仅仅考虑文本和结构信息并不足以获得含有丰富语义的源代码表达。2)解码阶段需要在规模庞大的词典中搜索目标单词,导致解码准确度降低,特别是一些不在词典中的目标词(Out Of Vocabulary, OOV),现有的工作一般是用指针网络实现的复制机制来缓解这个问题。
类型信息作为代码独有的内在属性,若能把其考虑在内,定能提供更多信息来丰富源代码的编码语义。另外不在词典的目标词一般会出现在抽象语法树的某些类型的节点上。所以我们提出了通过语法树节点类型引导注释文本生成的模型(Type Auxiliary Guiding, TAG)来帮助生成更高质量的注释文本。该模型包含了Type-associated Encoder和Type-restricted Decoder。并最后使用Hierarchical Reinforcement Learning(HRL)来训练学习。
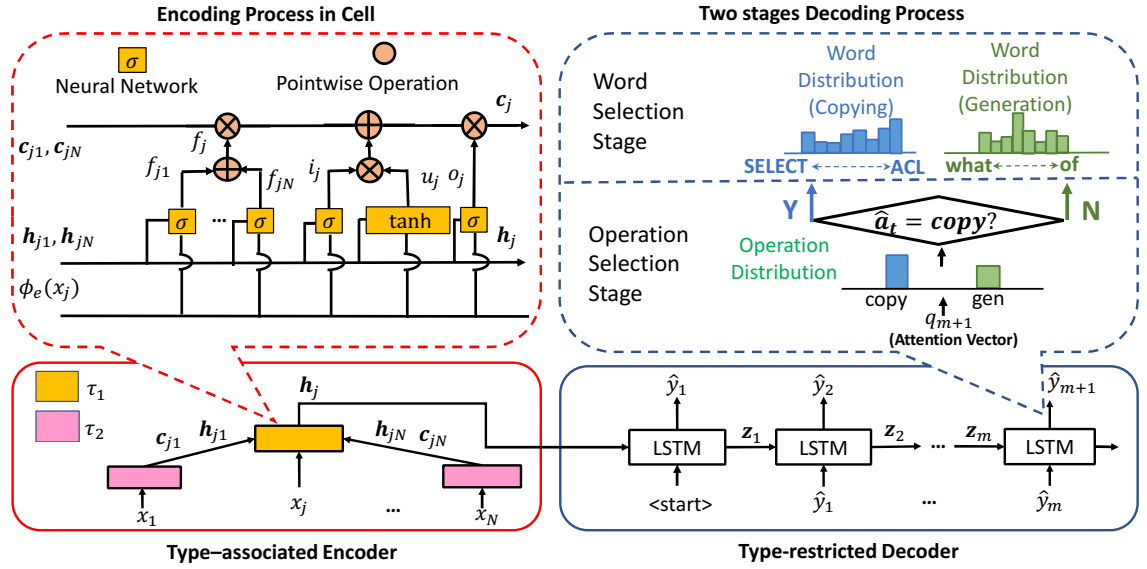
图二 TAG模型整体结构
模型
1, Type-associated Encoder
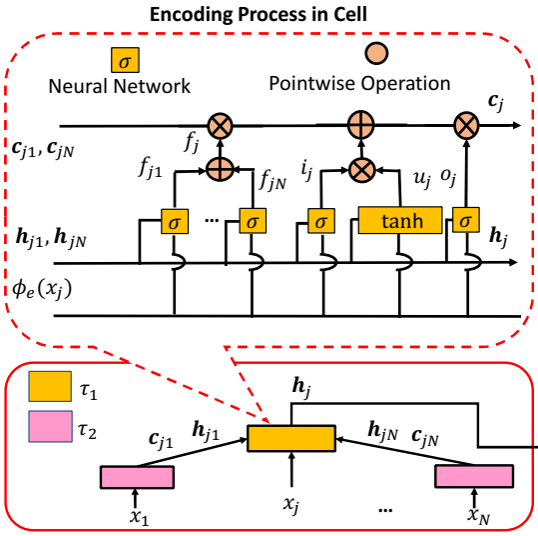
Type-associated Encoder在Tree-LSTM的结构上,引入了语法树节点类型。其包含输入门,输出门和遗忘门。而与一般的把数据属性作为特征输入不同的是,Type-associated Encoder把不同的节点类型作为不同的可训练学习的参数,在对语法树的每个节点进行编码时,根据节点类型使用对应的参数进行编码。而且Type-associated Encoder的遗忘门的权重是完全由每个节点的孩子节点决定的,与Tree-LSTM有所区别。Type-associated Encoder对语法树自底而上地编码每个节点,最后以根节点的隐状态作为整个抽象语法树的表编码表达传递至Type-restricted Decoder。
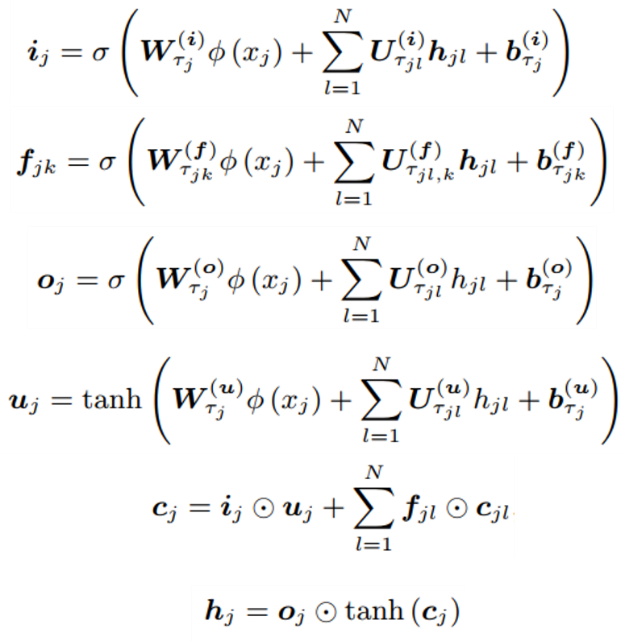
图三 Type-associated Encoder
2, Type-restricted Decoder
为了缓解OOV问题,Type-restricted Decoder也是采用指针网络实现复制机制。这样使得存在两个方向供解码器作解码输出:从抽象语法树中复制节点作为输出目标;或从词典生成目标单词的过程。所以实际上解码阶段包含两个阶段:1)操作选择阶段(Operation Selection Stage),该阶段会从一个二元分布(Operation Distribution)中选择一个操作,复制操作或生成操作,决定了是从抽象语法树进行复制还是从词典进行生成;2)单词选择阶段(Word Selection Stage),该阶段根据前一阶段的操作来从两个单词分布(Word Distribution),抽象语法树节点分布(Copying Distribution)或词典分布(Generation Distribution),中产生目标。该两个阶段均以基于注意力机制产生的注意力向量作为输入:
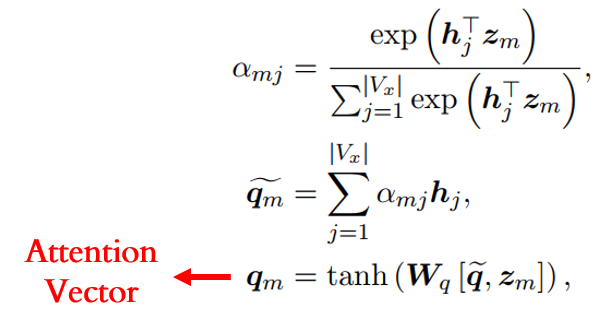
在操作选择阶段,该注意力向量经过一个全连接网络层产生:
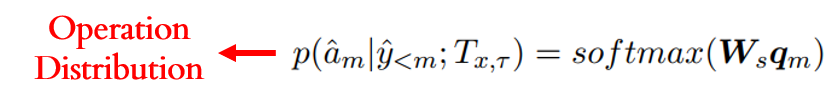
在单词选择阶段,该注意力向量进行类似操作(在复制过程还会与节点向量计算一个得分向量):
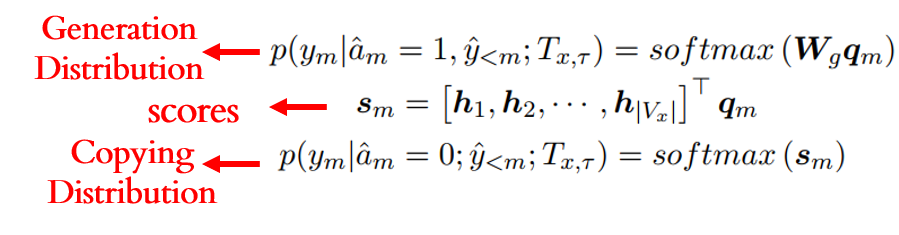
由于在复制过程中,目标单词很可能出现在某些类型的节点上,所以Type-restricted Decoder还复制过程中对某些类型节点进行过滤,使其成为无效节点,使得整个复制过程的搜索空间减少,提高搜索效率和准确度。具体地,使用一个基于类型的掩盖向量d,最后产生过滤了无效节点的节点分布:
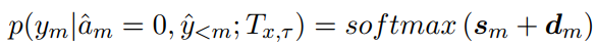
图四 对某些类型进行过滤,使其成为无效节点(灰色节点)
3, Hierarchical Reinforcement Learning
在监督学习中,模型在训练阶段使用交叉熵损失,而在测试阶段使用BLEU之类的不可求导的评测指标,这种不一致会导致模型的训练有偏差。考虑到这点,强化学习能够把测试阶段的评测指标作为奖励信号加入到模型的训练阶段中,可以作为解决方案。
可是由于第一个阶段(操作选择阶段)是一个中间过程,所以没有标签信息去指导该阶段的训练,这样无法构造奖励信号去反馈训练该阶段。TAG模型的目标函数是最大化奖励的期望:

从函数可知目标函数是由奖励信号和两阶段的联合分布(Two-stage Joint Distribution)构成。进一步的,联合分布是由操作分布和单词分布组成。单词分布依赖操作分布。这里可以看出两个阶段的分布都可以用相同的奖励信号去反馈。所以作者都使用来自第二个阶段(单词选择阶段)的标签去构造奖励信号去联合反馈训练两个阶段。

图五 Hierarchical Reinforcement Learning 示意图
实验
实验上,TAG模型在关于SQL、lambda逻辑表达式、Python三个数据集上进行评测,评测指标为BLEU和ROUGE。与其他基线模型相比,TAG模型具有显著的实现效果。
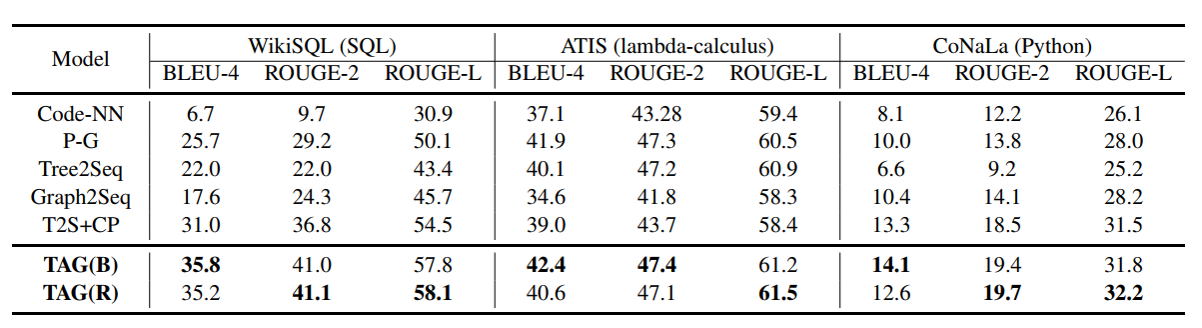
图六 TAG模型在三个数据集上的实验结果
总结
作者核心思想是引入源代码抽象语法树的节点类型信息,提出了TAG模型。该模型基于编码器-解码器框架。其中编码阶段根据节点类型对语法树进行编码,使得得到更丰富的源代码语义编码表达;在解码阶段根据节点类型对相关类型的无效节点进行过滤,使得复制过程减少搜索空间,提高搜索的效率和准确度。最后通过Hierarchical Reinforcement Learning训练模型解决解码阶段的两阶段训练问题。
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室