导语:
近日,广东工业大学计算机学院数据挖掘与信息检索实验室(DMIR)与新加坡国立大学、琶洲实验室(黄埔)、汕头大学合作的研究论文Matching without Group Barrier for Heterogeneous Treatment Effect Estimation被国际机器学习领域的旗舰级学术会议International Conference on Learning Representations(ICLR)接收。ICLR由图灵奖得主Yoshua Bengio和Yann LeCun创立,与ICML、NeurIPS并称机器学习领域的三大顶级会议。下面带来该论文的详细解读。

1 研究背景
在基于观测数据进行决策的过程中,准确估计异质因果效应至关重要,在个性化医疗、智能制造、商品推荐等领域具有重要的应用价值。异质因果效应估计面临的关键性挑战在于反事实潜在结果的缺失。对于任何特定个体,研究者只能观测到其在既定处理方案下的事实结果,而该个体在其他处理方案下的反事实结果则永远无法被直接获取。为了对反事实潜在结果进行精准预测,样本匹配方法作为一种非参数化的经典手段,凭借其简单易用的特性和较强的可解释性得到了广泛关注。匹配方法的核心思想在于数据分布的局部平滑性假设,即具有高度相似特征的个体,通常具有类似的潜在处理结果。通过在目标处理组中寻找与给定样本最接近的邻居,我们可以利用这些邻居的事实处理结果来预测给定样本在目标处理方案下的反事实结果。
然而,在面对复杂的实际观测数据时,传统匹配方法表现出明显的局限性。由于观测数据有限,且存在混淆偏差导致的各处理组之间的分布差异,现有方法在目标处理组中可能无法找到足够近的邻居,这意味着匹配到的样本与给定样本之间依然存在较大的距离。考虑到数据往往具有内在的流形结构,较大的距离通常无法准确刻画样本之间的真实关系,特别是潜在结果之间的关系,这限制了处理结果的预测性能。
针对上述挑战,本论文在样本匹配过程中打破了组别之间的壁垒,提出了一种无组别限制的样本匹配算法Matching withOut Group bArrier(MOGA),在所有的样本中寻找匹配近邻,而不考虑样本事实上接受的处理。通过这种方式,我们能够找到更为接近的样本,从而更为精准地捕捉样本之间关系,提升反事实预测的准确性。具体地,我们从理论上分析了所提匹配方法的估计误差,并从最优传输模型的视角对误差上界进行解释。以此为基础,我们提出了一个自最优传输模型来学习样本的匹配关系,进而最小化处理结果预测误差,以及异质因果效应估计误差。
进一步地,我们基于求解得到的最优传输矩阵构建了随机游走算法,在数据流形上对事实处理结果进行扩散,利用信息传播机制对样本的反事实处理结果进行精准预测。与此同时,为了利用处理结果引导传输代价的学习,强化传输代价与处理结果之间的一致性,我们将事实处理结果引入最优传输模型,提出了表征与处理结果协同的最优传输模型。我们在合成、半合成、真实数据集上进行了实验,利用多种指标评估算法性能,验证了所提算法的有效性。
2 方法描述
2.1 无组别限制的样本匹配
为了预测给定样本在目标处理方案
下的反事实潜在结果,传统的匹配方法在目标处理组中寻找给定样本的近邻,并通过近邻的事实结果进行反事实结果预测。然而,在实际场景中,往往难以在目标处理组中找到足够近的邻居,尤其是在观测样本数据不足的情况下,或者是在混淆偏差导致的各处理组间具有较大分布差异的情况下。尽管我们总是可以在目标处理组中找到一个距离不够近的邻居,数据的流形结构决定了这种较远的距离无法准确刻画样本潜在结果之间的关系,导致反事实结果预测不准确。
针对这一问题,我们打破样本匹配过程中的组别壁垒,提出了一种无组别限制的样本匹配算法Matching withOut Group bArrier(MOGA),在所有样本中寻找给定样本的近邻,无论接受的是否是目标处理方案
。通过这种方式,我们能够找到更为接近的邻居,而这种局部平滑的流形结构能够更为准确地刻画样本处理结果之间的关系。
在找到近邻
之后,根据近邻的处理结果
,给定样本的处理结果可以利用如下方式进行预测
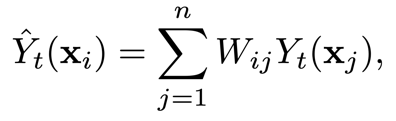
其中权重
反映了样本间匹配程度的强弱。通过下面的理论,我们分析了这种反事实处理结果预测方法的误差上界
从这一理论可以看出,为了最小化处理结果的预测误差,可以基于表征
下的距离度量,将匹配程度
作为优化变量,最小化上述误差上界。
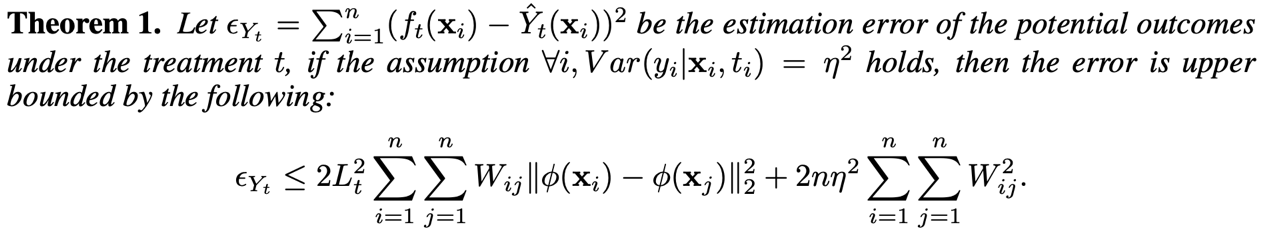
更重要的是,我们发现这一误差上界能够从最优传输(Optimal Transport)理论的视角进行解释。通过构造传输矩阵
,最小化误差上界可以建模为下面的自最优传输(self optimal transport)问题
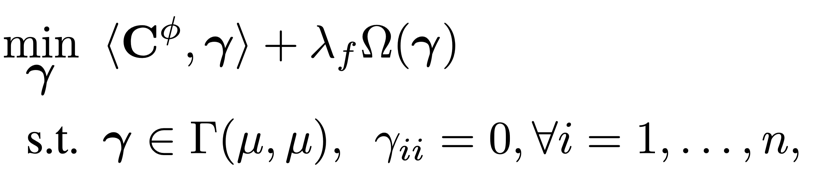
其中
是传输距离矩阵,定义为
,
是Frobenius范数的平方,作为正则项诱导较为平滑性的传输矩阵。与传统的最优传输考虑两组数据不同,这里的自最优传输考虑一组数据内部的概率质量传输,并构造了额外的约束条件
,避免样本自我传输导致的平凡解问题。
进一步地,我们在下面的理论中分析了异质因果效应估计的误差上界

接下来,我们讨论如何利用最优传输矩阵进行反事实结果预测,以及如何在最优传输模型中引入事实处理结果来学习传输代价。
2.2 基于信息传播的反事实结果预测
上述最优传输模型得到的最优传输矩阵反映了样本之间的匹配程度,能够用来进行反事实结果预测。然而,在预测给定样本在目标处理t下的反事实潜在结果时,匹配到的近邻可能来自于各个处理组,这些样本在目标处理t下的潜在结果可能是未知的。针对这一问题,我们借鉴半监督学习策略,利用最优传输矩阵γ来刻画数据流形上的局部相似性,并构造随机游走算法,通过信息传播机制迭代更新样本的反事实预测结果。
最优传输问题的特性决定了传输矩阵γ具有双重随机特性(doubly stochastic),因而可以用来构造状态转移概率矩阵
,并以此为基础构造亲和度矩阵
,用于下面的潜在结果信息扩散过程
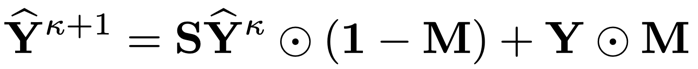
其中,
是事实结果的掩码矩阵,用于保留已知的事实结果信息。通过这种方式,事实结果能够遵循数据的流形结构进行传播,最终得到所有样本在目标处理
下的潜在结果。
2.3 基于事实结果引导的传输距离学习
从理论分析中可以看出,异质因果效应的估计误差依赖于样本之间的传输代价
。为了使距离相近的样本具有相似的潜在处理结果,我们希望传输代价能够更好地捕捉样本在潜在处理结果上的差异。
基于这一思想,我们构造了样本在事实处理结果上的差异矩阵
,并提出下面的协同最优传输模型,引导传输距离的学习
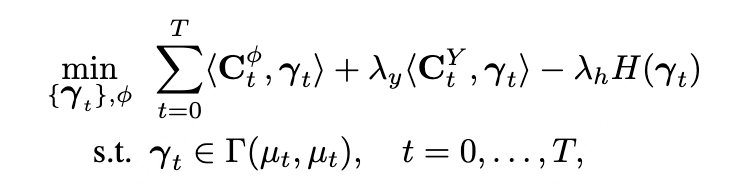
其中,样本在表征空间中的传输代价与事实处理结果的差异,具有一致的最优传输矩阵,使得具有较小传输代价的样本具有相似的潜在结果,提升样本匹配方法在处理结果预测上的准确性。
3 实验结果
下列表格展示了算法MOGA在合成数据集、半合成数据集以及真实数据集上的实验结果。可以看出,提出的算法在不同类型数据集和多种性能指标上,均能得到较好的结果。图1给出了部分样本的可视化匹配结果。
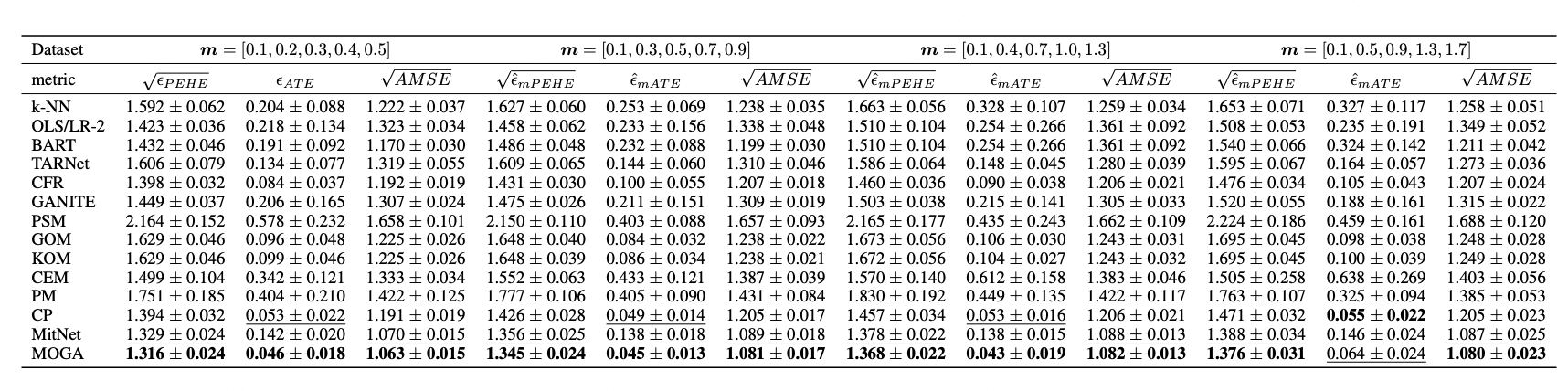
表1 MOGA在合成数据集上结果
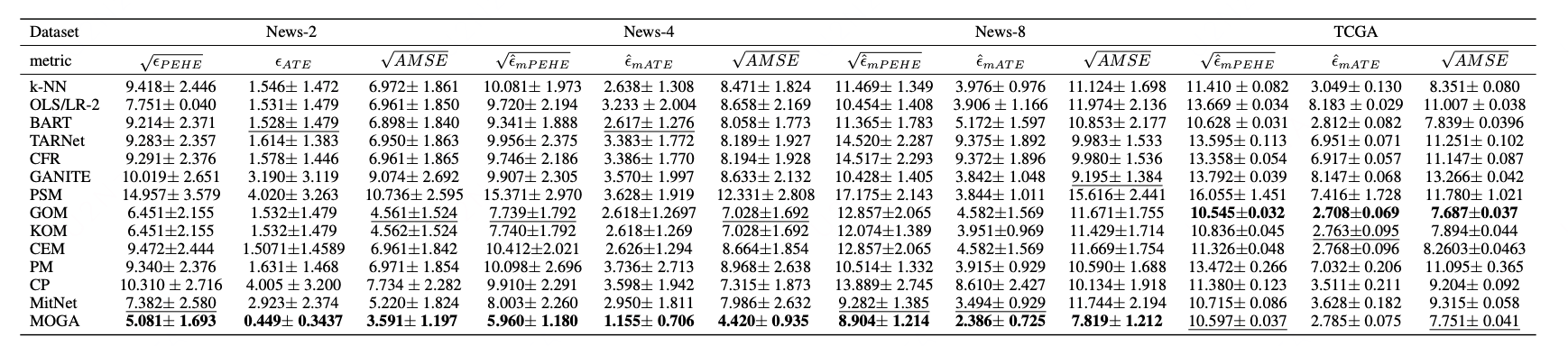
表2 MOGA在半合成数据集News和TCGA上结果
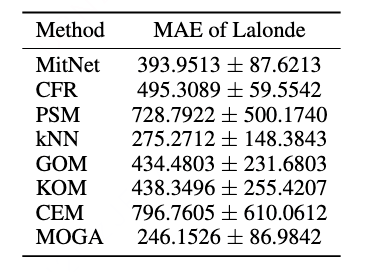
表3 MOGA在真实数据集Lalonde上结果
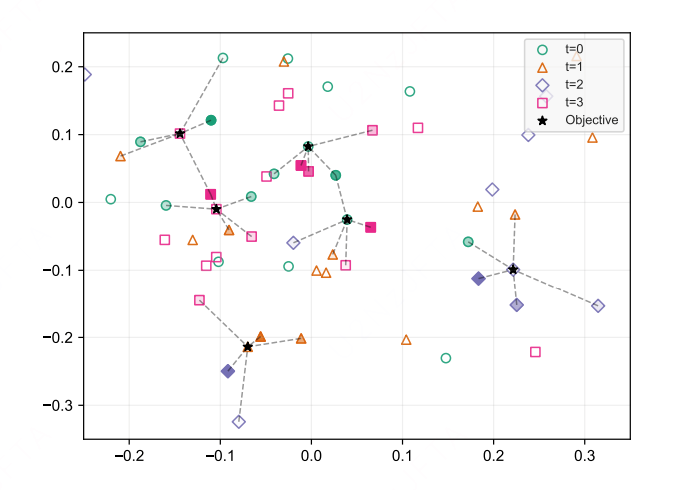
图1 MOGA匹配过程可视化
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室