导语:
近日,广东工业大学计算机学院数据挖掘与信息检索(DMIR)实验室与鹏城实验室、MBZUAI、Khalifa University、A*STAR、清华大学合作的论文 Time Series Domain Adaptation via LatentInvariant Causal Mechanism 被机器学习领域的国际顶级学术期刊IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 接收。TPAMI期刊由国际电气和电子工程师协会(IEEE)创办,是CCF A类期刊,也是中科院SCI一区TOP期刊。下面带来该论文的详细解读。

1 研究背景
在时间序列域自适应任务中,数据由来自不同领域的时间序列样本构成,且存在显著的分布偏移。其核心难点主要源于跨域分布的异质性与时间依赖的域不变性挖掘。跨域分布的异质性是指源域与目标域的边际分布或条件分布存在差异,且高维数据(如视频、传感器流)中观测变量间往往缺乏直接因果关系,这进一步加剧了分布偏移的复杂性。时间依赖的域不变性挖掘则意味着,尽管不同域的观测数据分布不同,但驱动数据生成的潜在因果机制具有域稳定性,如何捕捉这种深层不变的时间因果依赖是关键挑战。因此,一个重要的研究方向是如何有效融合高维时间序列的潜在因果结构与跨域对齐策略,通过识别低维潜在变量及其因果关系,突破传统方法对观测变量的依赖限制,实现更稳健的域自适应知识迁移。
针对上述挑战,近年来提出了诸多时间序列域自适应方法,它们多基于观测变量的统计特性或因果关联建模,采用分布对齐等策略捕捉域不变信息。这些方法多局限于低维数据场景,默认观测变量间存在直接因果关联,却忽略了高维数据中观测变量往往缺乏直接因果关系的现实。鉴于高维时间序列(如视频、传感器流)往往由低维潜在变量生成,且潜在因果机制具有域稳定性,忽略潜在变量的建模与跨域因果对齐,将会使域自适应性能受到显著限制。
基于上述思想,我们提出了潜在因果对齐(LCA)模型,通过将高维观测变量映射到低维潜在变量,识别低维潜在变量、重构其稀疏因果结构,并对齐跨域潜在因果机制,解决高维时间序列域自适应的核心挑战。
在技术上,我们构建了一个基于变分推断的统一学习框架,对时间序列的潜在动态过程进行建模,该框架通过编码器–解码器结构将高维观测映射到潜在空间。在此基础上,我们实现了潜在变量的可识别性,并借助跨域因果不变机制,实现对域不变因果结构的有效建模。大量的实验研究表明,我们的LCA模型在九个真实数据集上优于最先进的时间序列域自适应方法。
2 潜在因果对齐(LCA)
本研究从潜在因果格兰杰多分布的数据生成出发,可以将跨域分布偏移与时间因果依赖进行解耦。具体而言,我们刻画高维时间序列
由低维潜在变量
通过可逆的非线性映射生成:
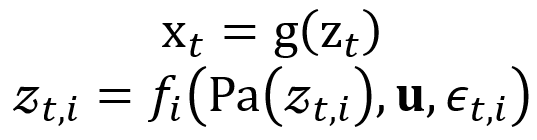
为了同时学习潜在表示与因果结构,LCA 采用基于变分推断的时序生成建模框架,通过编码器–解码器结构近似分布,优化目标源证据下界(ELBO):
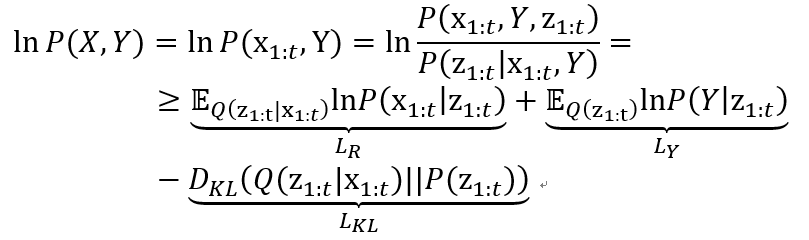
为剔除虚假因果关系,模型引入潜变量格兰杰因果稀疏约束
,通过
惩罚雅可比矩阵冗余元素,确保仅保留真实因果依赖。
针对跨域适配需求,设计潜变量因果对齐约束
,利用掩码矩阵
聚焦域间因果结构差异,实现跨域不变因果机制的对齐。
最终,我们得到目标函数如下:
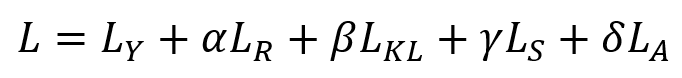
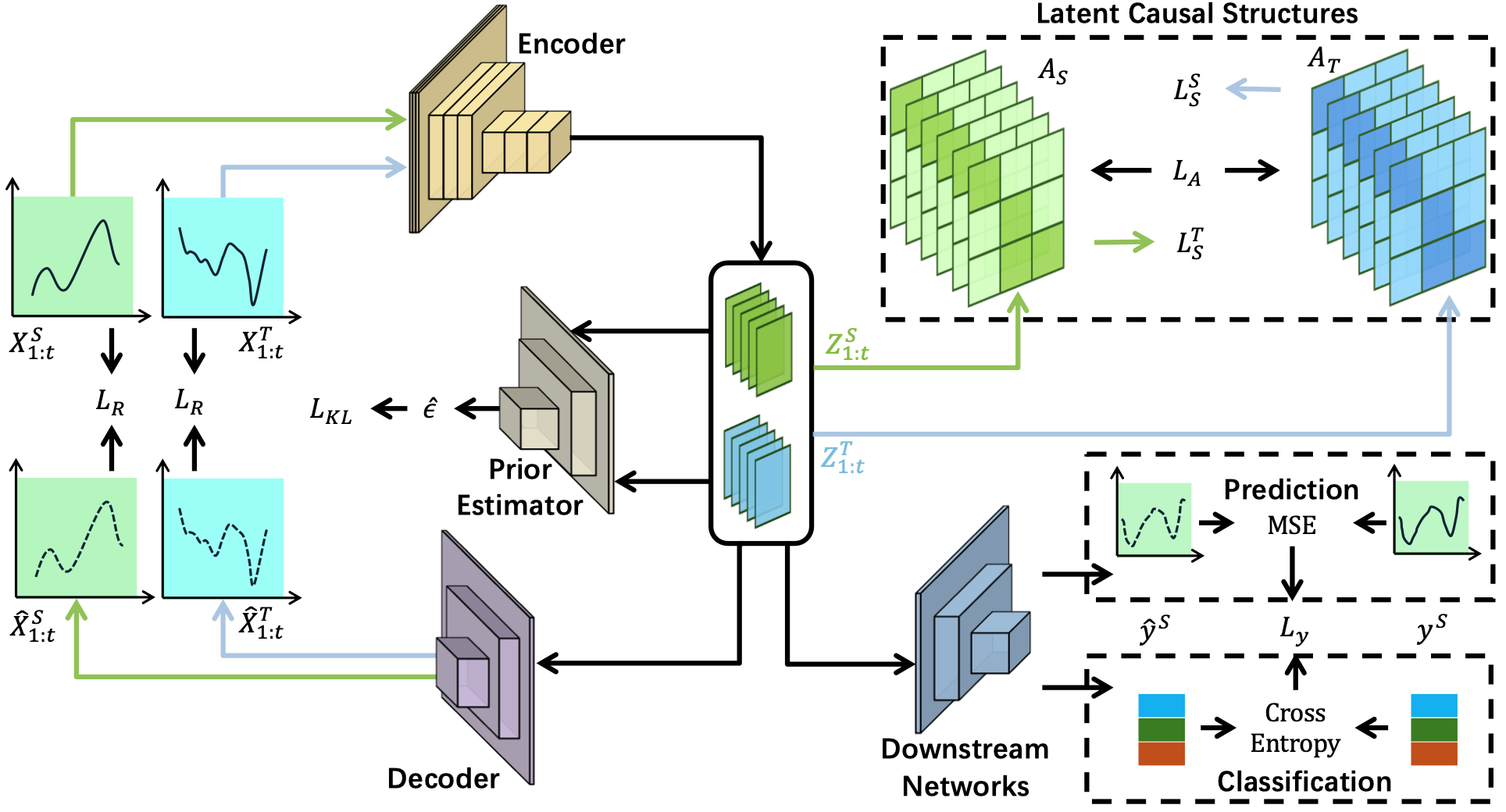
图 1 因果潜在对齐模型框架
3 实验结果
因果潜在对齐模型在九个真实数据集上优于最先进的方法,证明了所提出方法的有效性。
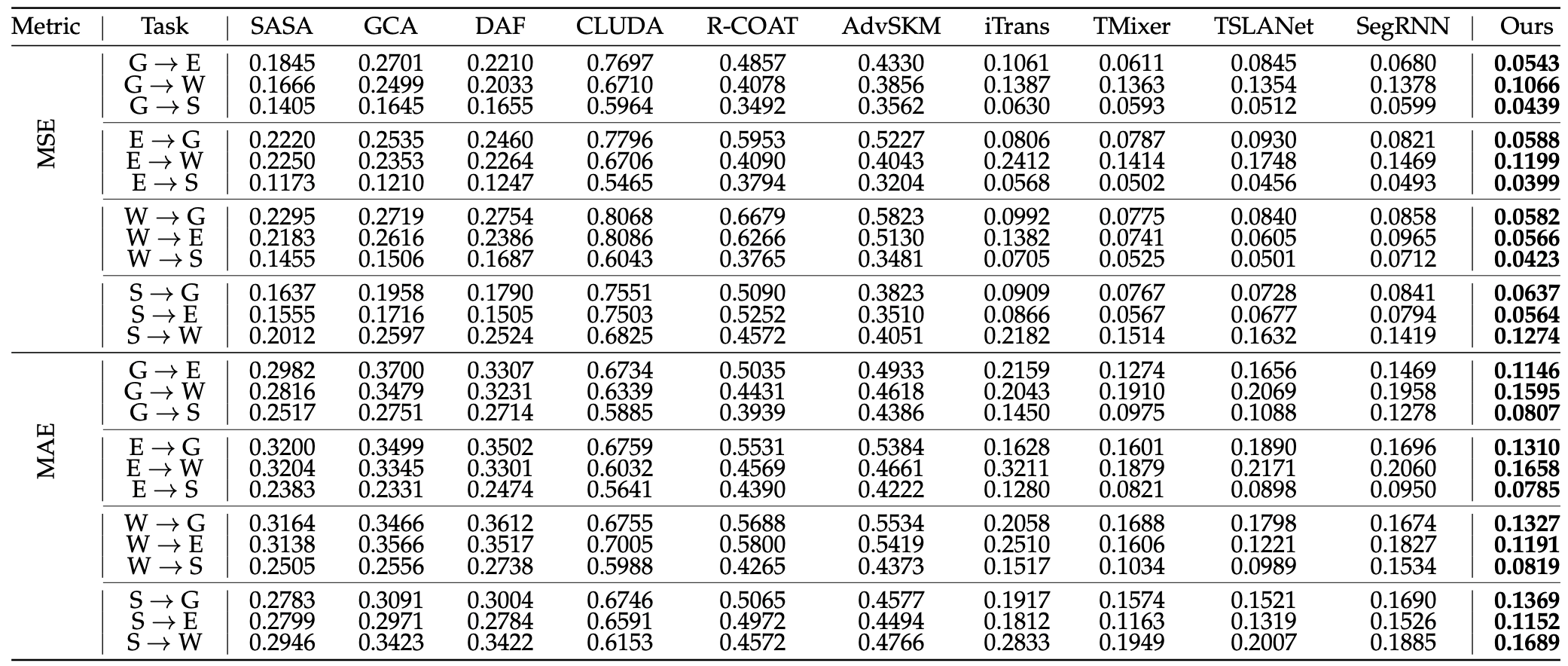
表1 LCA方法在Human Motion上的实验结果

表2 LCA方法在ETT上的实验结果
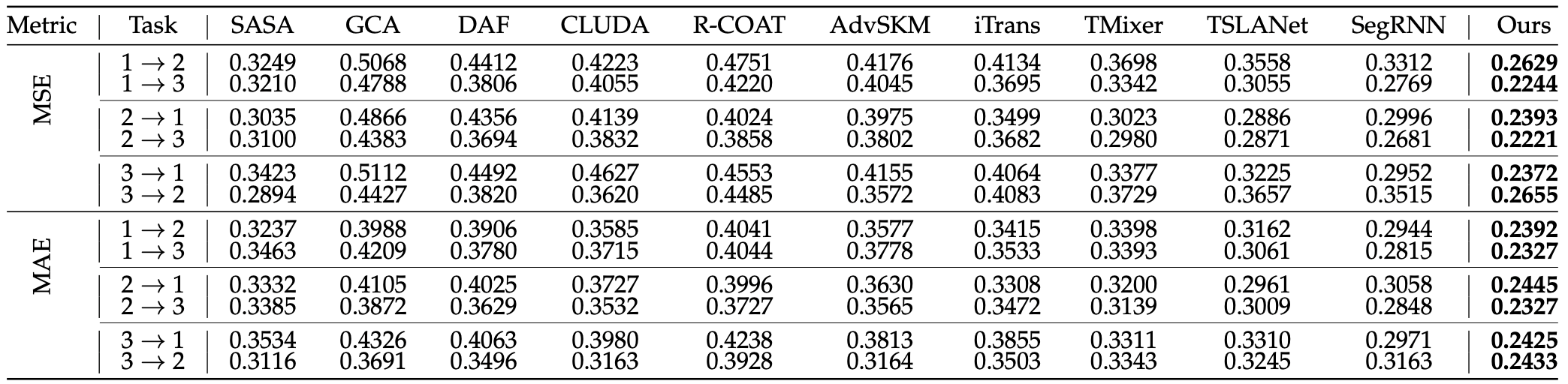
表3 LCA方法在PEMS上的实验结果
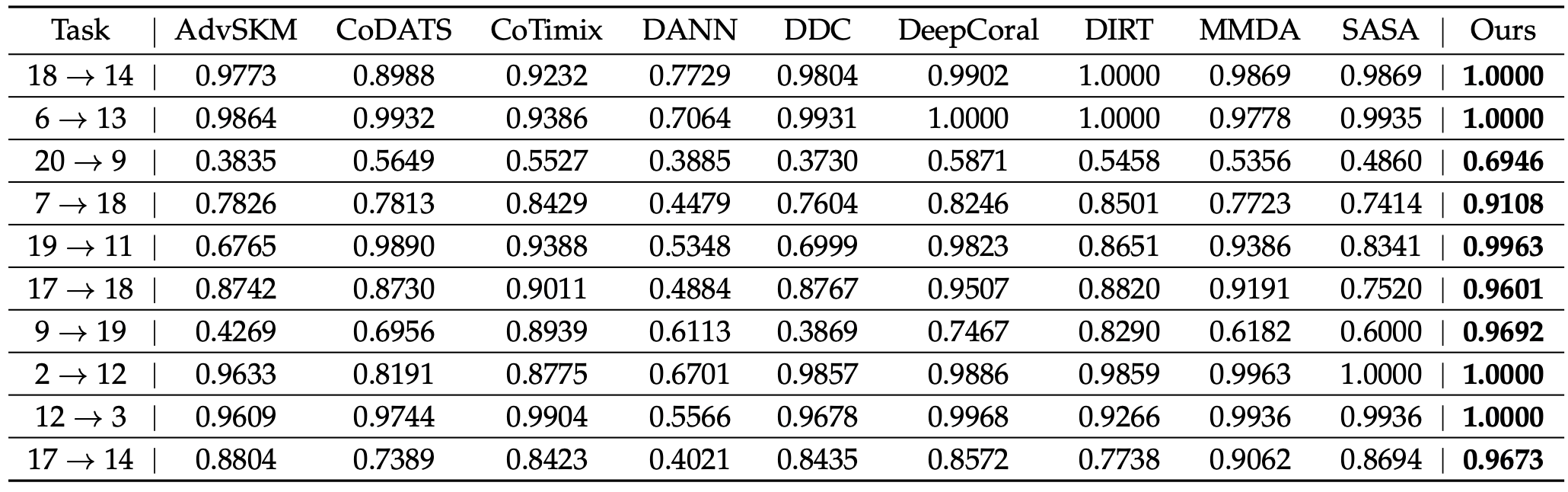
表4 LCA方法在UCIHAR上的实验结果
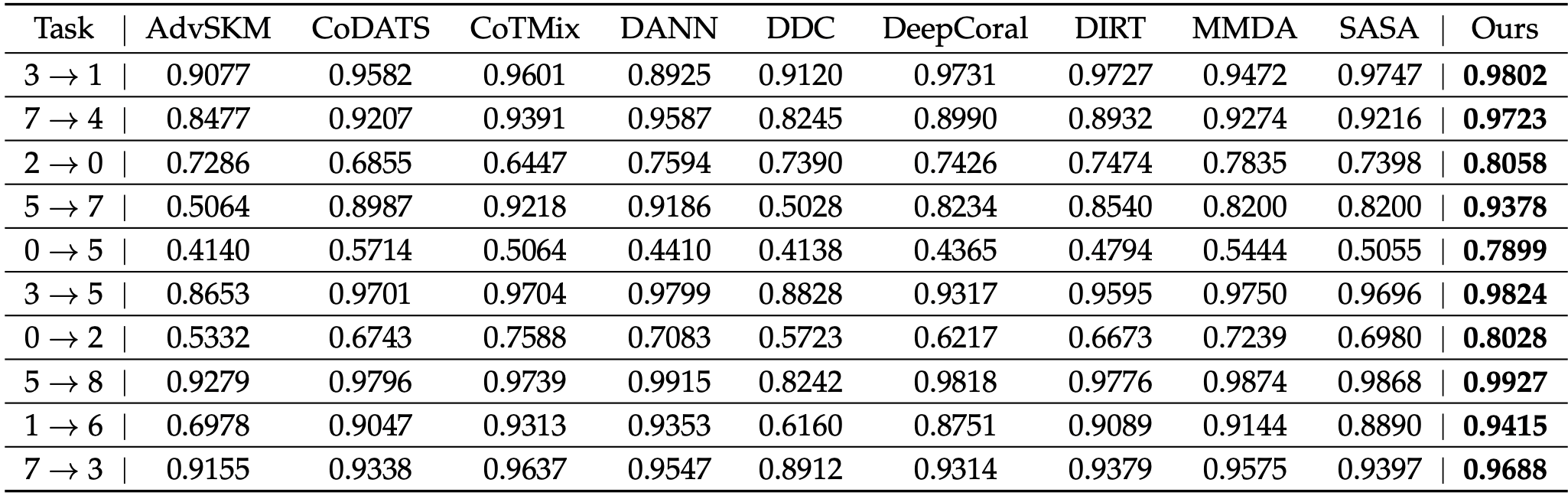
表5 LCA方法在HHAR上的实验结果
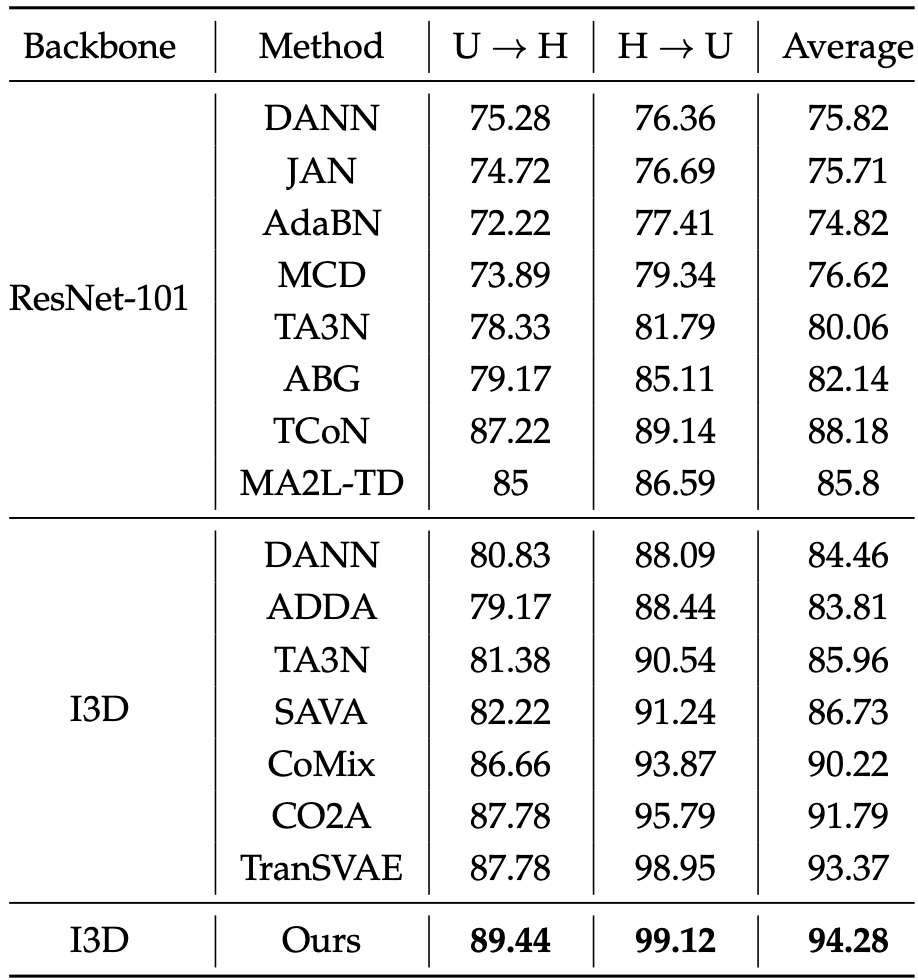
表6 LCA方法在HMDB-UCF上的实验结果
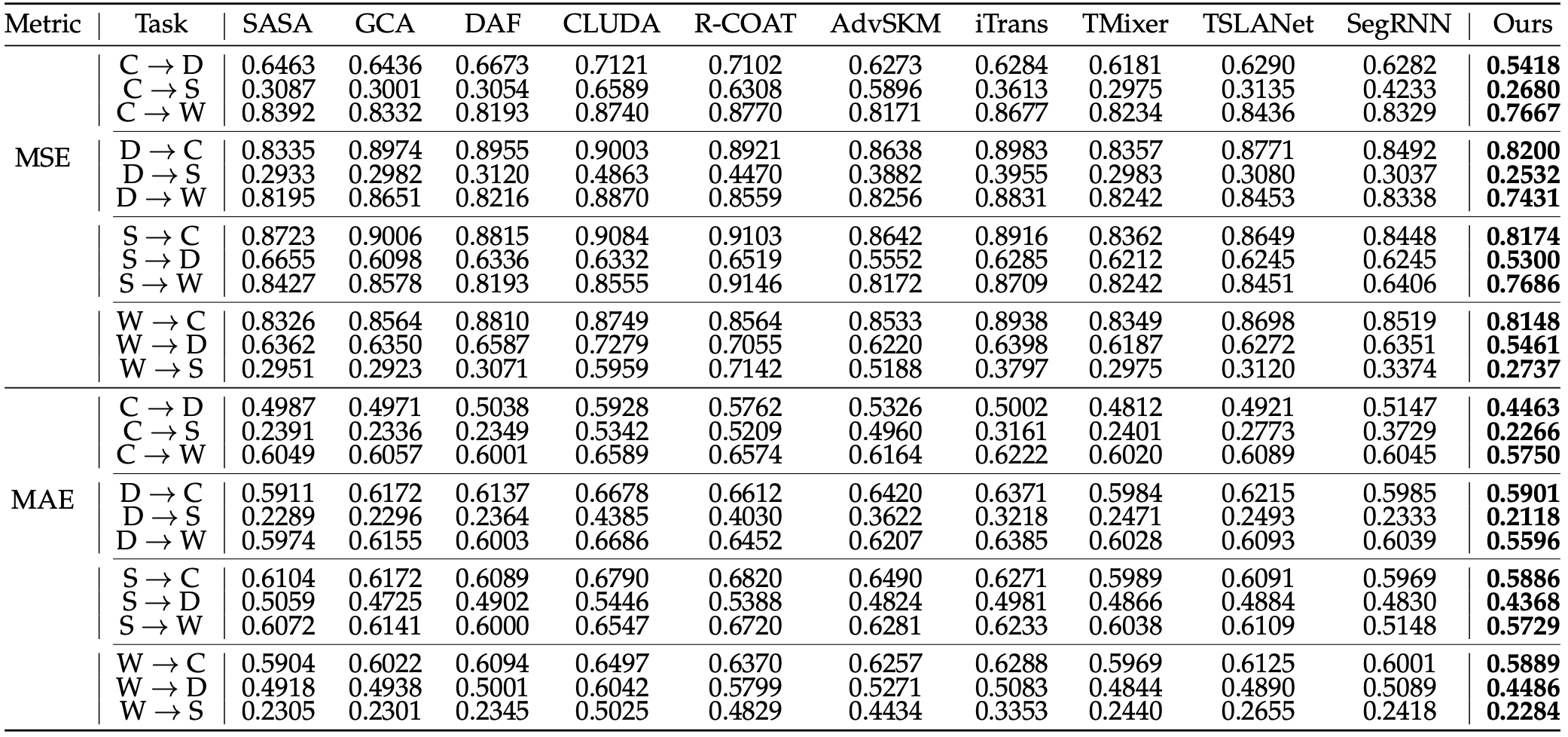
表7 LCA方法在PPG-DaLiA上的半监督实验结果
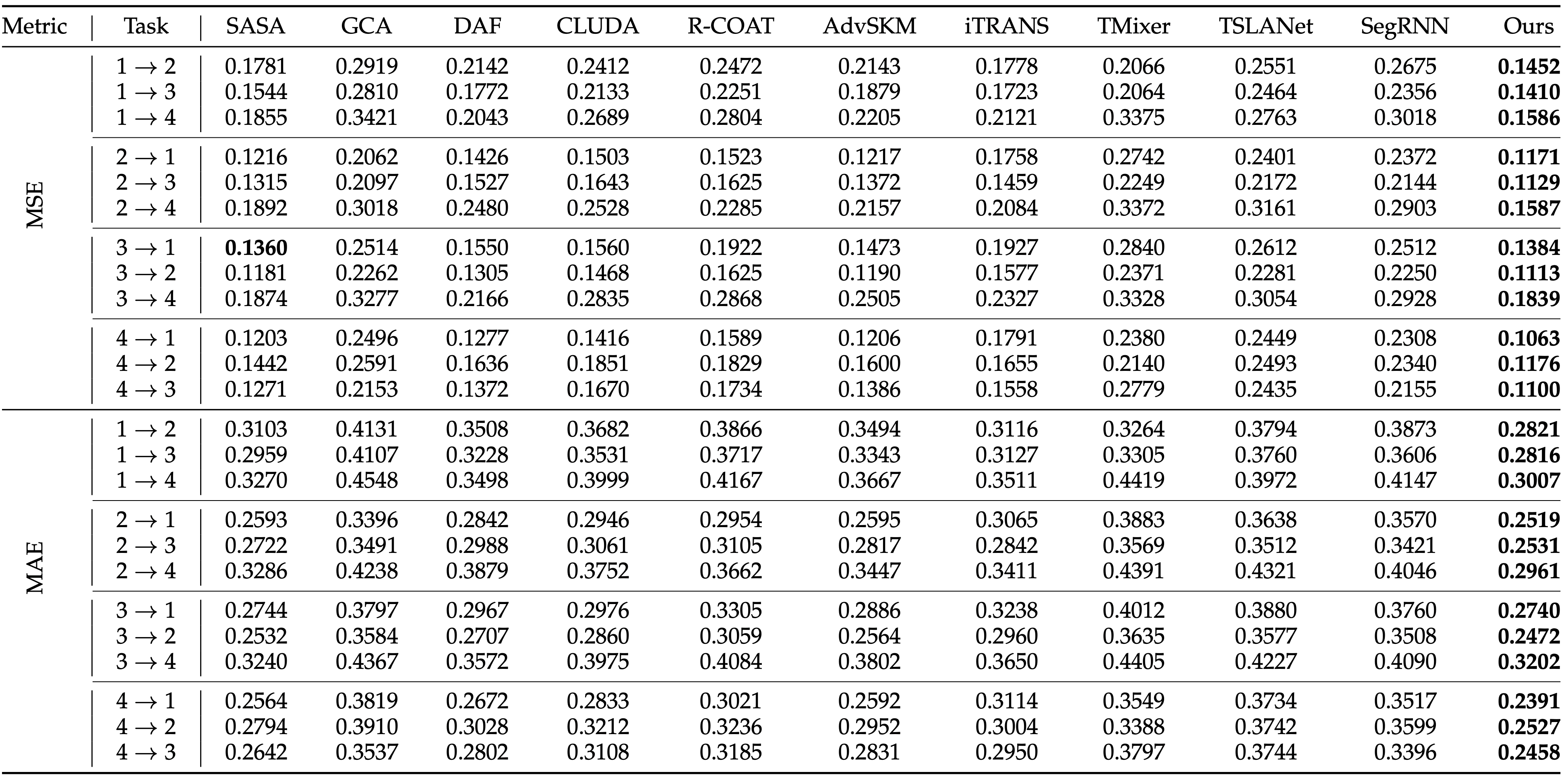
表8 LCA方法在Electricity Load Diagrams上的实验结果
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室