导语:
近日,广东工业大学计算机学院数据挖掘与信息检索(DMIR)实验室与鹏城实验室、MBZUAI、汕头大学合作的论文 Causal View of Time Series lmputation: Some ldentification Results on Missing Mechanism 被国际人工智能联合会议IJCAI 2025 (International Joint Conferences on Artificial Intelligence)接收。IJCAI是人工智能领域顶级国际学术会议之一,也是CCF-A类会议。下面带来该论文的详细解读。

1 研究背景
尽管数据驱动的深度模型在时间序列分析和大规模应用(如交通、天气和物联网)方面取得了显著的性能,这些模型的性能通常依赖于完整的数据支持。然而,实际场景中的传感器故障会导致时间序列数据缺失,使得现有算法难以直接应用。为了解决这一问题,研究者提出了时间序列填充方法。该方法的核心思想是通过观测数据和缺失值标记,来推断时间序列的完整数据分布。
时间序列填充方法的早期研究主要依赖于统计建模技术,而近期基于深度神经网络的方法可划分为两大范式:预测式方法和生成式方法。例如,预测式方法通过构建循环神经网络(RNN)、卷积神经网络(CNN)以及Transformer等时序建模架构,旨在捕捉时间序列变量间的时空依赖关系;此外,生成式方法则利用变分自编码器(VAE)、生成对抗网络(GAN)和扩散模型等深度生成模型,直接学习完整时间序列数据的概率分布。这些深度学习模型通过联合建模缺失值的时间演化过程以及潜在变量到观测数据的生成机制,实现了对时间序列缺失值的填充。
在实际应用中,时间序列数据可能会受到各种类型的缺失数据机制的影响,如MCAR(完全随机缺失)、MAR(随机缺失)和MNAR(非随机缺失)。尽管现有时间序列填补方法已取得显著进展,多数研究基于单一缺失机制假设构建模型,未能充分考虑不同缺失机制的本质差异。以遵循MNAR机制的医疗为例,患者病情恶化可能导致随访中断,从而在治疗后期产生与健康状况相关的系统性缺失数据。若在此类场景中错误采用MCAR假设模型,由于忽略了缺失原因与观测值之间的潜在关联,填充结果往往存在显著偏差。因此,针对不同缺失机制建立差异化建模策略,是提升填充性能的关键所在。
为了更好地利用缺失机制,我们探索了不同的缺失机制并提出了相应的方法,形成了一个名为DMM的通用框架。首先,我们系统分析了完全随机缺失(MCAR)、随机缺失(MAR)和非随机缺失(MNAR)三种机制下的数据生成过程。基于此,我们构建了基于变分推理的概率生成模型,通过规范化流神经架构实现对潜在变量的可识别建模。理论分析表明,该方法在MAR和MNAR机制下能够有效识别时间演化潜在变量及其缺失原因潜在变量。为验证模型有效性,我们在包含多种缺失机制的大规模半合成数据集上进行了系统实验,结果表明DMM框架在各项评估指标上均显著优于现有最优方法。
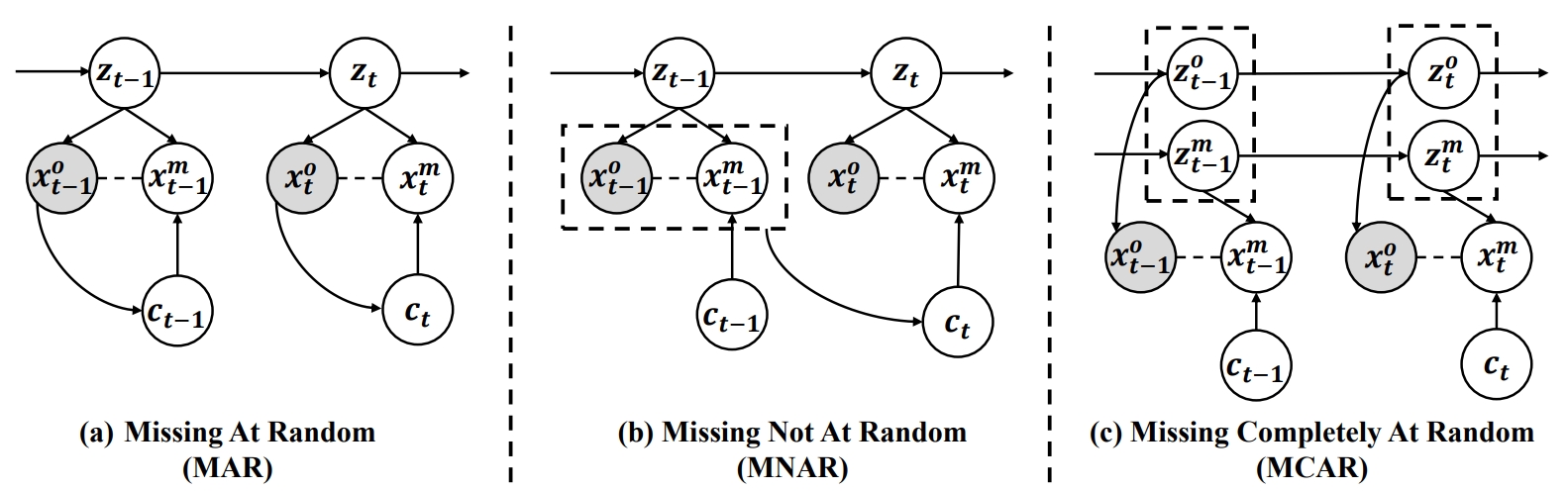
图 1 不同缺失机制数据生成过程
2 时序填充模型(DMM)
我们引入了不同缺失机制下时间序列数据的数据生成过程,如图1所示。其中
是描述时间依赖关系的时间潜在变量。
是观测变量,
是缺失数据,
表示缺失原因变量。根据数据生成过程,在以下假设成立的情况下,提出可识别性理论。

图 2 可识别性假设
通过可识别理论确定先验网络设计后,本文再根据基于数据生成过程的证据下界(ELBO)确定模型的自动编码器:
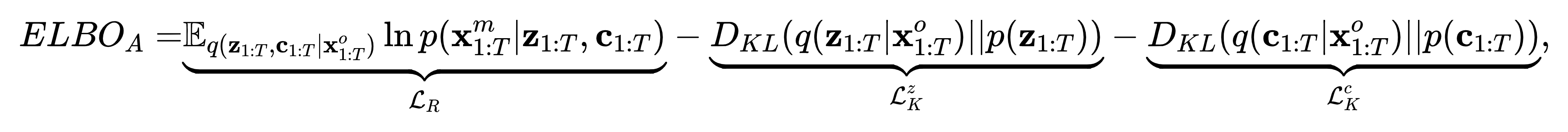
基于这些数据生成过程,我们引入了如图3所示的DMM框架,该框架对MAR和MNAR机制的数据生成过程进行了建模。
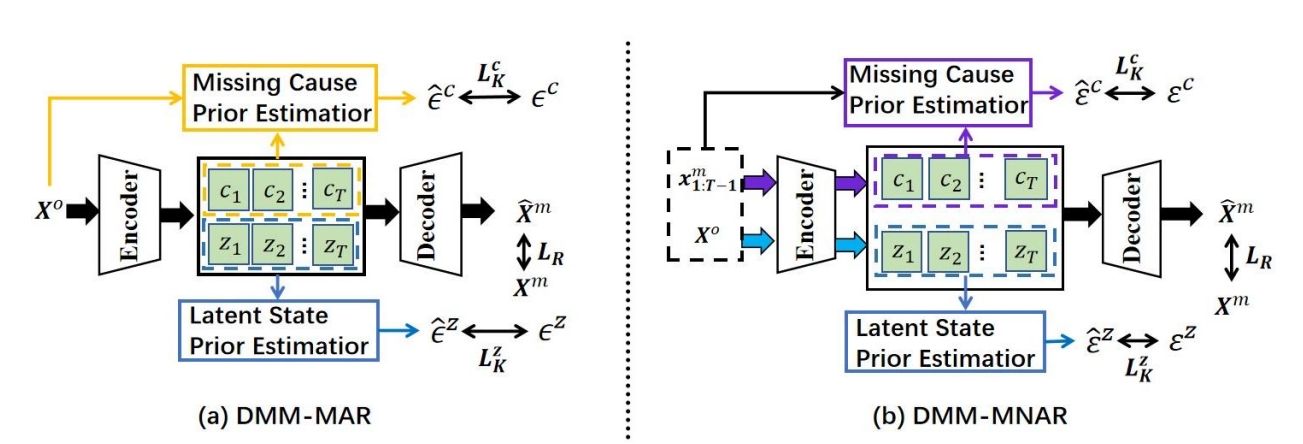
图 3 时序填充模型框架
3 实验结果
时序填充模型(DMM)在多个真实数据集,如Exchange,Weather优于最先进的方法。对于每个数据集,我们根据MAR和MNAR的缺失机制生成掩码矩阵模拟缺失值。同时,我们使用三种不同的缺失率,如0.2、0.4和0.6。此外,我们使用监督学习和无监督学习方法进行训练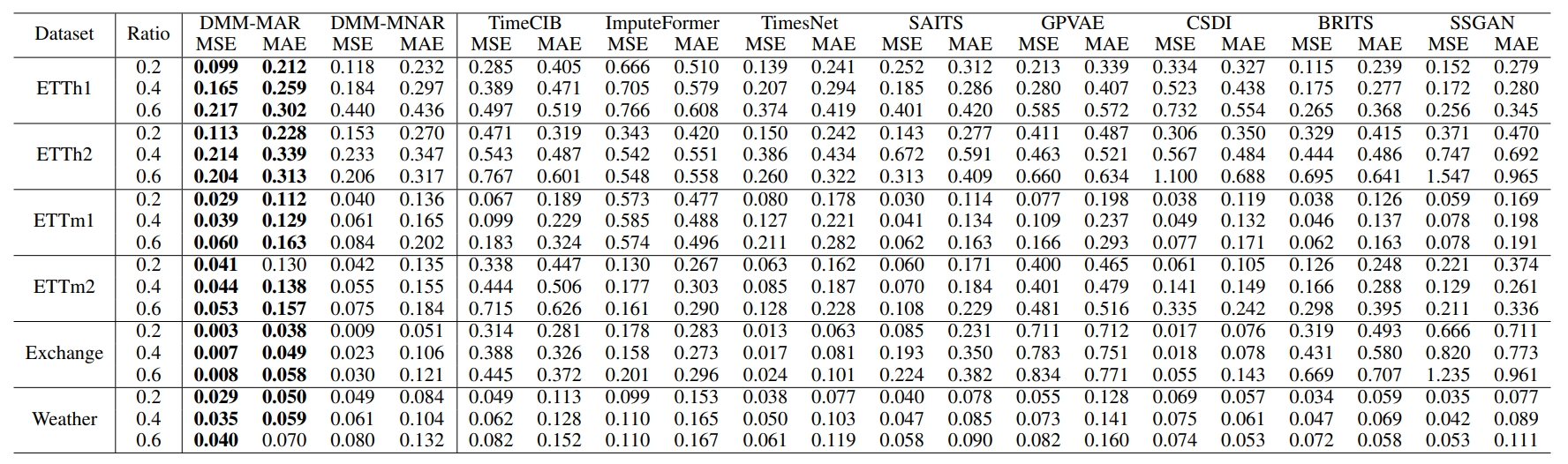
表1 在MAR缺失机制下,对不同缺失率的数据集进行无监督学习的实验结果
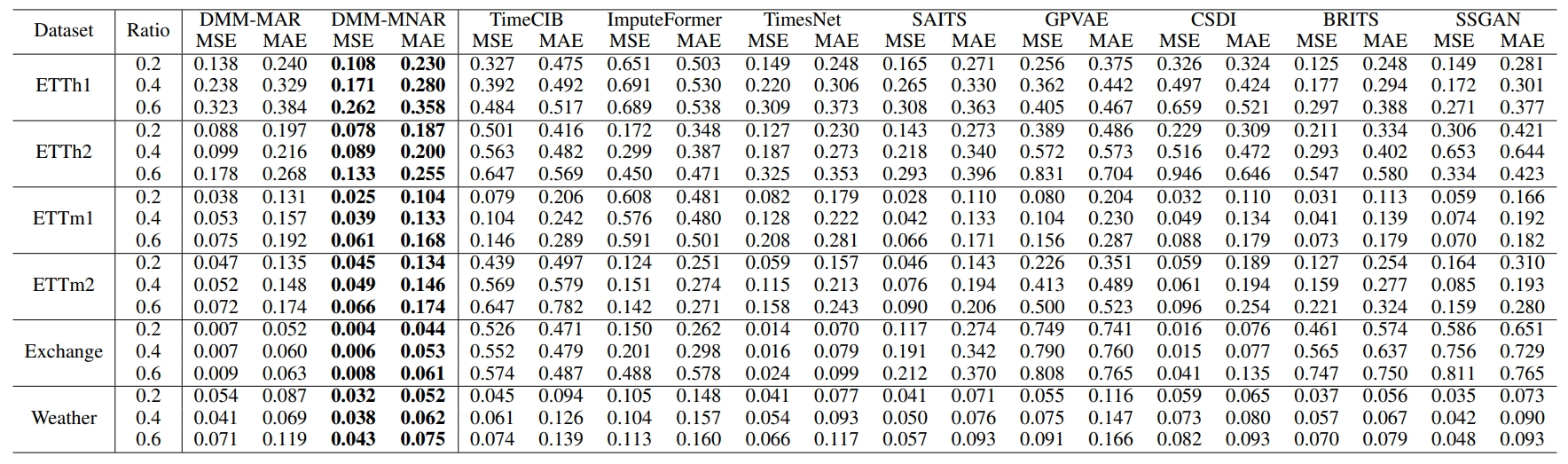
表2 在MNAR缺失机制下,对不同缺失率的数据集进行无监督学习的实验结果
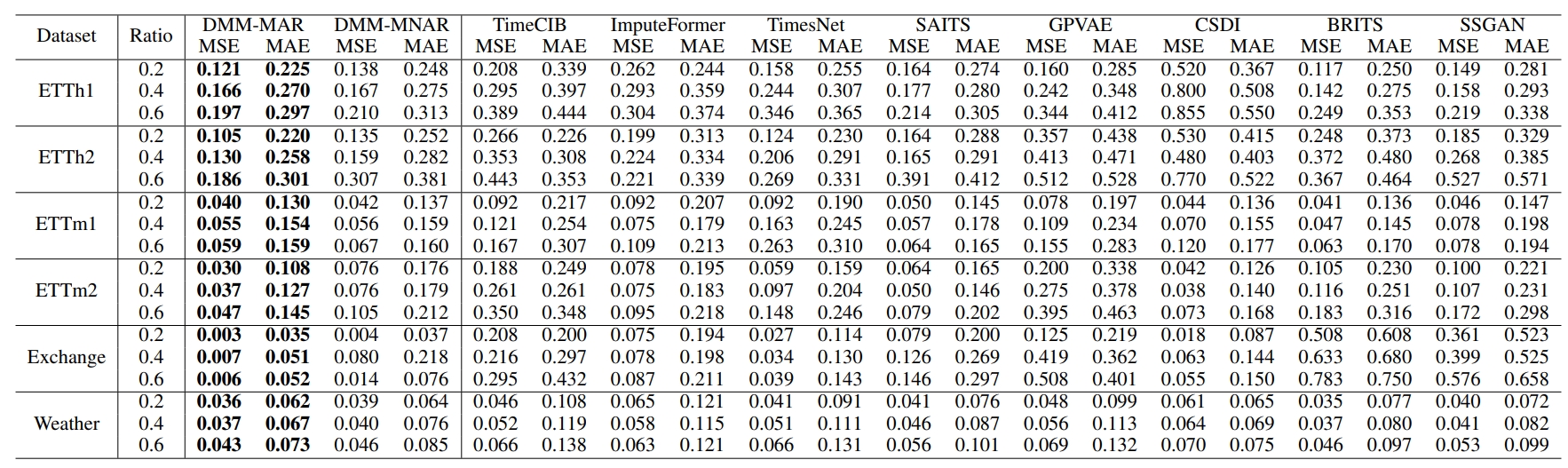
表3 在MAR缺失机制下,对不同缺失率的数据集进行监督学习的实验结果
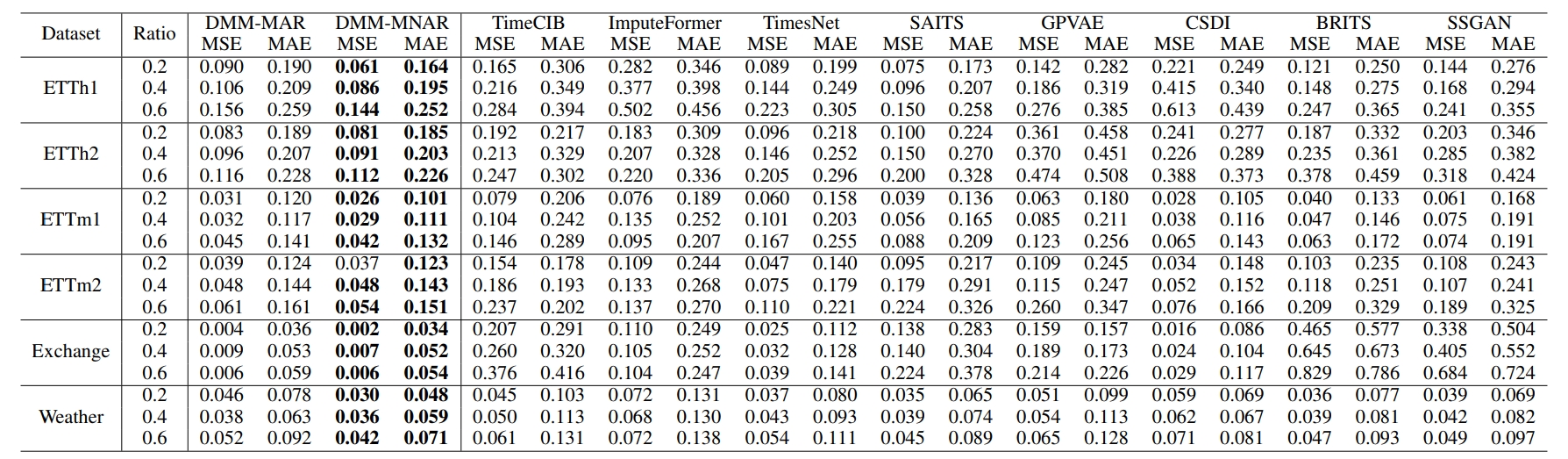
表4 在MNAR缺失机制下,对不同缺失率的数据集进行监督学习的实验结果
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室