导语:
近日,广东工业大学计算机学院数据挖掘与信息检索(DMIR)实验室与汕头大学、华为诺亚方舟实验室、鹏城实验室合作的论文Causal-aware Large Language Models: Enhancing Decision-Making through Learning, Adapting and Acting被国际人工智能联合会议IJCAI 2025 (International Joint Conferences on Artificial Intelligence)接收。IJCAI是人工智能领域顶级国际学术会议之一,也是CCF-A类会议。下面带来该论文的详细解读。

1 研究背景
近年来,以GPT和LLaMA为代表的大语言模型(Large Language Model,LLM)在文本生成、问答等任务中展现出惊人能力,甚至被探索用于游戏控制、机器人规划等决策场景。这类模型通过海量数据预训练,能够存储丰富的世界规律知识,但在需要深度推理和动态适应的复杂任务中却暴露了明显短板。传统大语言模型依赖“下一个词预测”的机械逻辑,虽然擅长续写文本,却难以像人类一样结构化分析因果关系。此外,模型的知识固化于预训练数据中,无法根据环境反馈实时更新认知,面对新场景时容易陷入僵局。
为了突破这一限制,近年来研究者尝试将大语言模型与强化学习结合,但效果仍然有限。传统强化学习方法通过试错学习策略,虽能适应动态环境,却存在学习效率低下的问题——往往需要百万级训练步数才能完成简单任务,且缺乏对“砍树获得木材、木材制作工具”这类因果链的高层理解。而结合大语言模型的强化学习方法,虽然能生成任务目标提升策略可解释性,却受限于模型本身的“猜词”模式,可能产生“石头直接变木材”等违背真实因果的推理错误,更无法在环境变化时动态修正错误认知。此外,也有研究者将大量的先验知识提供给LLM,帮助其快速理解环境,虽然其效果有明显提升,但是这类方法仍然无法提供一个合适的方式供LLM与动态的环境交互。
针对上述挑战,本文从人类的决策过程得到启发,将因果信息嵌入大语言模型策略决策过程,提出了Causal-aware LLMs框架。框架共分为三个阶段:Learning、Adapting、Acting。在Learning阶段,LLM从可部分观测马尔可夫序列中抽取因果关系并构建因果图;在Adapting阶段,由于LLM环境问题产生的错误、以及不确定的因果关系会在这一阶段通过因果干预机制得到验证并修改;在Acting阶段,由因果关系指导的目标会驱动策略学习,从而实现LLM与动态环境的交互以及利用环境中的因果信息进行决策。

图1 传统现有方法与Causal-aware LLMs
2 Causal-aware LLMs框架
Causal-aware LLMs包含了三个阶段:Learning、Adapting、Acting。
在 Learning阶段,利用大语言模型(LLM)在智能体与环境动态交互的过程中,逐步抽取因果信息,并将这些因果信息建模为因果结构。具体而言,采用上下文学习和少样本学习方法设计提示词,旨在引导模型准确提取因果关系。
在 Adapting阶段,通过因果干预技术动态修正LLM生成的初始因果图,解决因“幻觉”或环境复杂性导致的认知偏差。该过程的核心是引入因果科学中的do算子,通过强制改变某一变量的状态(例如执行“砍树”动作),切断其他干扰因素,直接观察目标变量(如木材数量)的变化,从而验证因果关系的真实性。这一机制使得LLM能够基于环境反馈动态更新因果图。
在 Acting 阶段,融合前两个阶段学习到的因果知识,通过大语言模型驱动目标导向模块实现策略学习和目标生成。具体而言,首先基于因果图中包含的因果关系,利用LLM根据提示词和因果知识生成目标,分解复杂任务为多个子目标,帮助智能体逐步完成任务。接着智能体通过因果感知策略采样动作。为缓解奖励稀疏问题,引入了语义对齐的奖励增强机制,通过当前目标与环境观测的余弦相似度计算奖励,从而提供更密集的反馈信号,提升探索效率和因果一致性。

图2 Causal-aware LLMs框架
3 实验结果
本文在开放世界游戏 Crafter 上进行了系统性的实验,如下所示,验证了Causal-aware LLMs框架的有效性。图2的实验结果表明,得益于因果知识引导的策略学习,Causal-aware LLMs在多个复杂成就上表现出了显著的优势。另一方面,如图4、表2所示,因果知识在训练过程中显著提高了训练效率:对于同一成就,Causal-aware LLMs 能以更少的交互步骤、更快的收敛速度完成任务,体现出更强的样本效率与泛化能力。

表1 Causal-aware LLMs及对比方法在Crafter基准上的实验效果
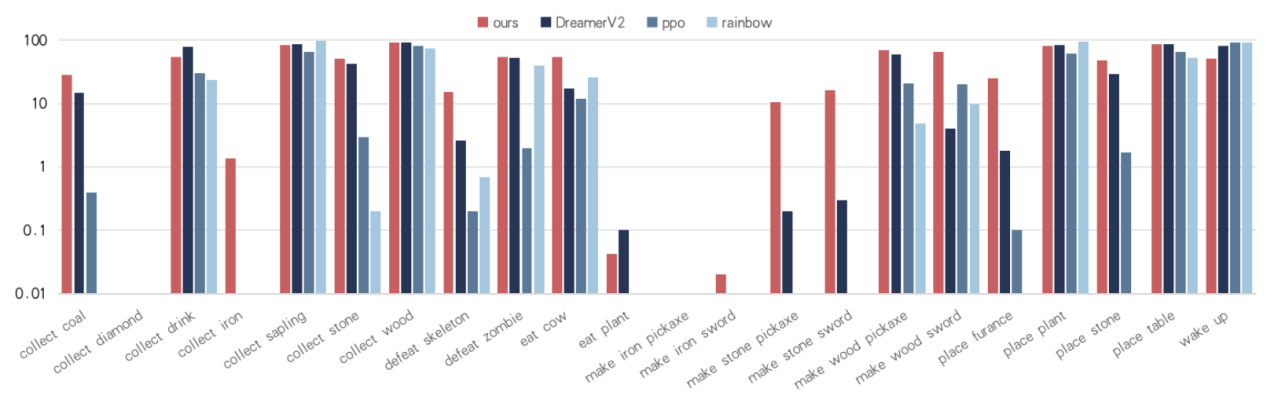
图3 Causal-aware LLMs及对比方法在22个成就上的得分

图4 训练过程中成就解锁效率分析

表2 因果知识对于模型训练的增益分析
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室