导语:
近日,广东工业大学计算机学院数据挖掘与信息检索(DMIR)实验室与MBZUAI、汕大、CMU合作的论文Learning Disentangled Representation for Multi-Modal Time-Series Sensing Signals 被CCF-A类会议 WWW 2025 ( The ACM Web Conference )接收。WWW是计算机综合交叉领域的顶级会议之一。下面带来该论文的详细解读。

1 研究背景
现有大多数时间序列分析方法均针对同质数据设计,假设时间序列采样自同一模态。然而,在物联网(IoT)、医疗保健和金融等多个实际应用中,从多种模态采样且不兼容这些方法的异质时间序列数据也十分常见。为建模多模态时间序列数据,主流解决方案是从观测到的时间序列信号中解纠缠模态共享和模态特有的隐变量。
针对模态共享与模态特有时间隐变量的解纠缠问题,现有方法已形成多种技术路径。其中主流方向之一是基于对比学习来学习模态共享表征。考虑到模态特有表征在下游任务中的重要性,已有研究人员使用正交约束并同时利用模态共享和模态特有表征。总体而言,这些方法通常假设模态共享与模态特有隐变量是正交的,因此可通过不同的对比学习约束实现解纠缠。
尽管这些方法在多个应用中表现优异,但在现实场景中,模态共享与模态特有隐空间的正交性可能难以满足。图 1 以糖尿病患者的生理指标为例,其中时间序列数据包含脑相关和心脏相关信号。具体而言,图 1(a)表示真实数据生成过程,胰岛素浓度对血压和心率的因果方向反映了糖尿病如何引发心脏病和高血压并发症。如图 1(b)所示,现有方法对估计的隐变量施加正交约束,而忽略真实隐空间源之间的依赖关系,导致解纠缠不彻底并影响下游任务性能。
为应对上述隐空间源依赖的挑战,我们提出了一种多模态时间解纠缠框架,以在可识别性保证下估计真实隐变量。具体而言,我们首先利用成对多模态数据建立隐变量的子空间可识别性,继而借助历史隐变量的独立影响进一步证明隐变量的分量可识别性。基于上述理论结果,我们开发了多模态时间解纠缠模型(MATE),该模型将变分推理神经架构与模态共享和模态特有先验网络相结合。通过在多模态时间序列数据的广泛下游任务中进行验证,本文提出的MATE 模型性能超越了现有的先进方法,证明了其在实际应用中的有效性。
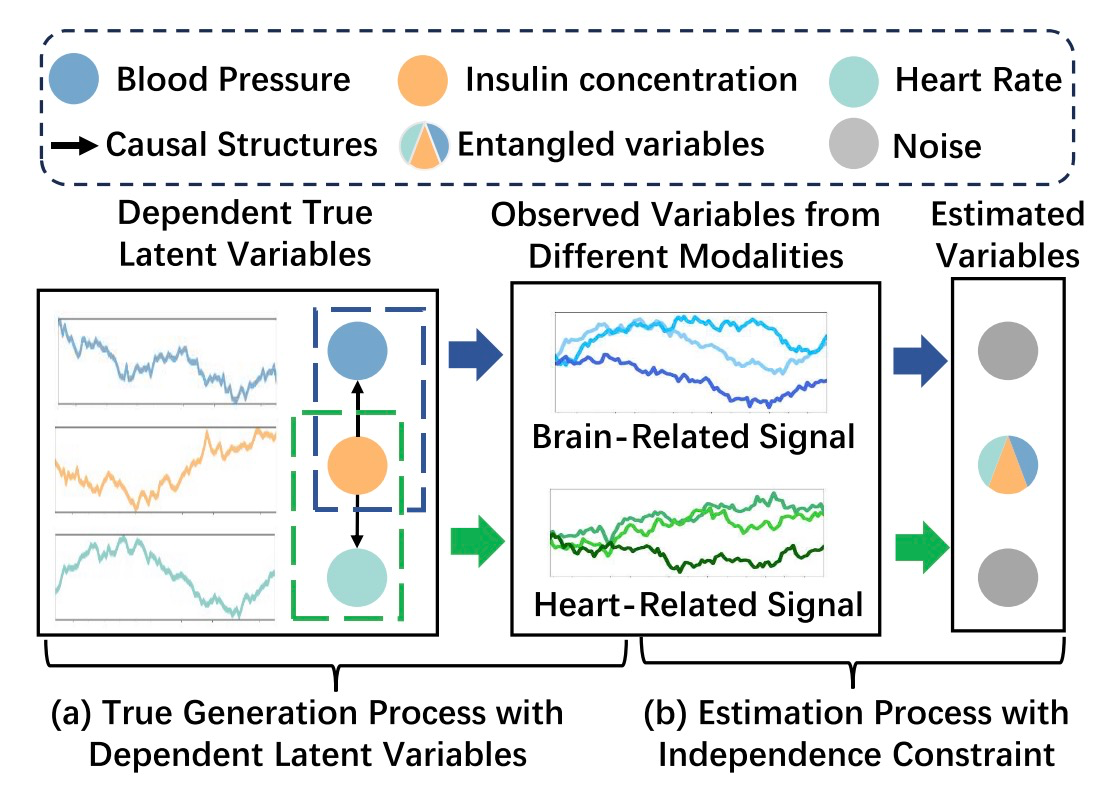
图 1 糖尿病患者的生理指标的例证
2 多模态时间解纠缠模型
为了展示如何学习多模态时间序列数据的解纠缠表征,我们引入如图 2 所示的多模态时间序列的数据生成过程。其中
为模态观测数据,
为模态共享隐变量,
为模态特有隐变量。
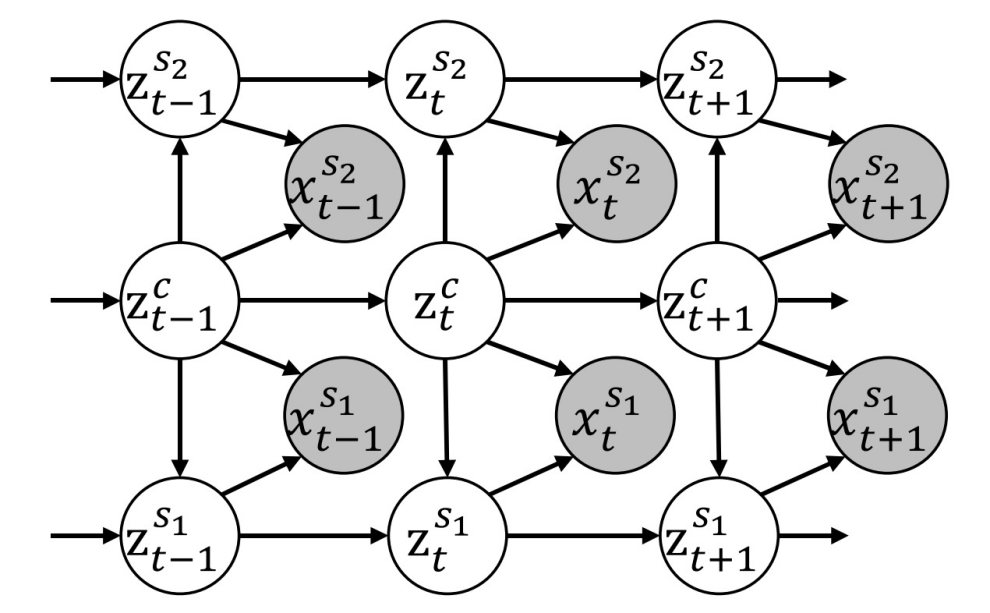
图 2 多模态时间序列数据生成过程
根据数据生成过程,在以下假设成立的情况下,提出block- wise 和component-wise可识别理论。基于多模态数据配对特性,可证明模态共享与特有隐变量block- wise可识别;并利用历史隐变量的充分变化性,进一步证明模态隐变量的component-wise可识别。

图 3 bloc-wise可识别性假设

图 4 component-wise可识别性假设
通过可识别理论确定先验网络设计后,再根据基于多模态时间序列数据生成过程的证据下界(ELBO)确定模型的自动编码器:
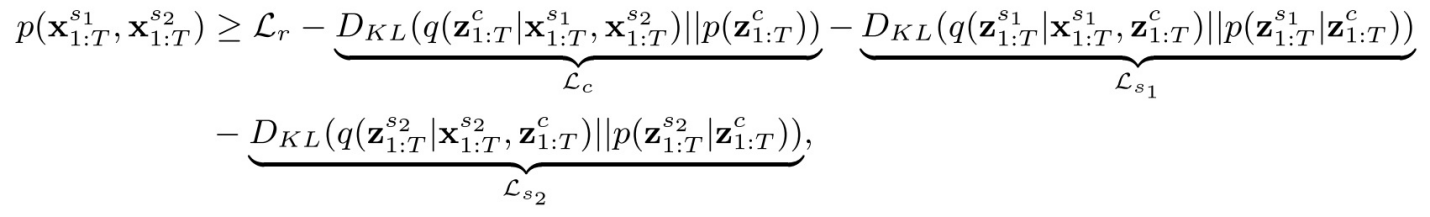
其中
表示重构损失,可以形式化为:
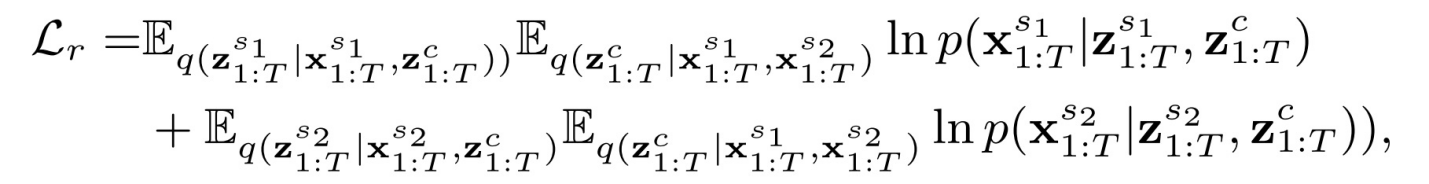
此外,由于模态共享隐变量应该尽可能相似,因此我们进一步设计了一种模态共享的约束,如下所示,这限制了模态共享的潜在变量在任意两对模态之间的相似性。
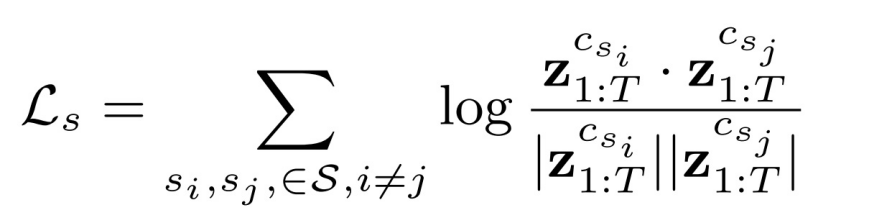
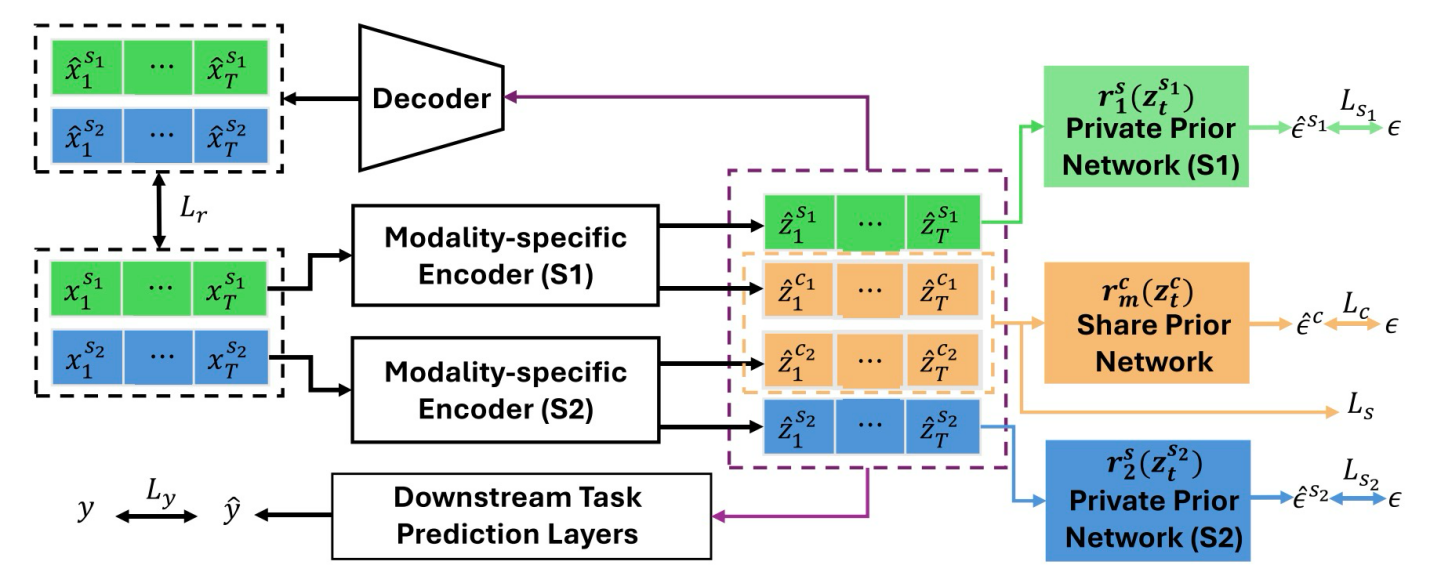
图 5 多模态时间解纠缠模型
3 实验结果
多模态时间解纠缠模型(MATE)框架在12个已发布的数据集上进行了各种下游任务,例如分类、聚类,自监督等,其实验结果均达到SOTA,证明了所提出方法的有效性。
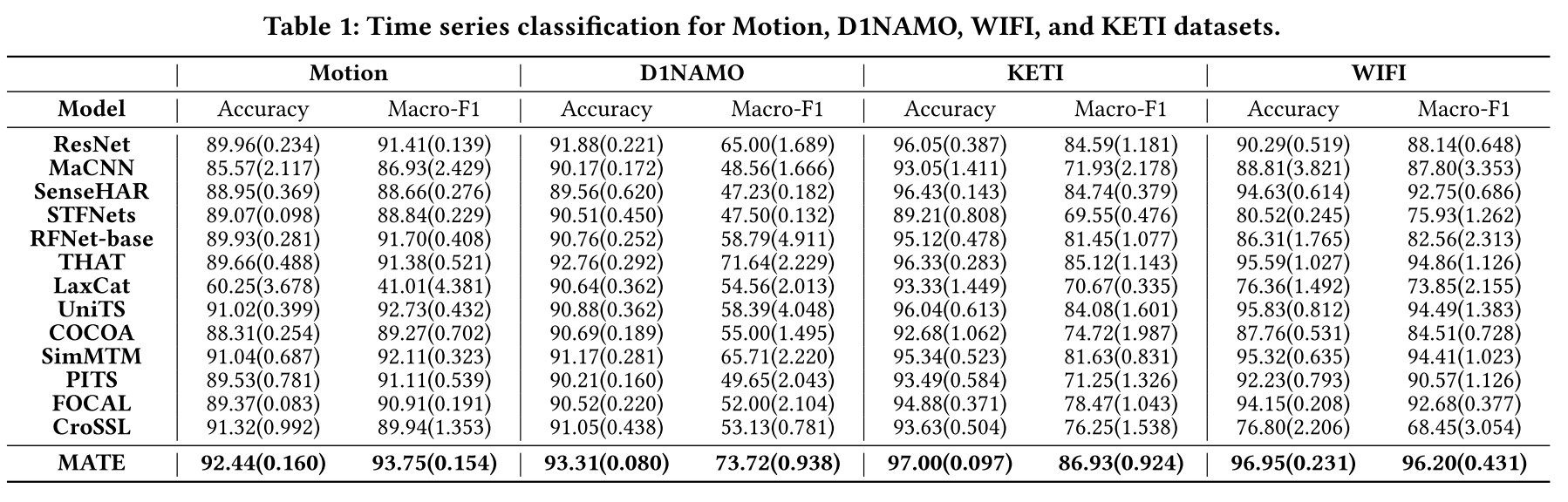
图 6 多模态时间解纠缠模型框架在分类的结果
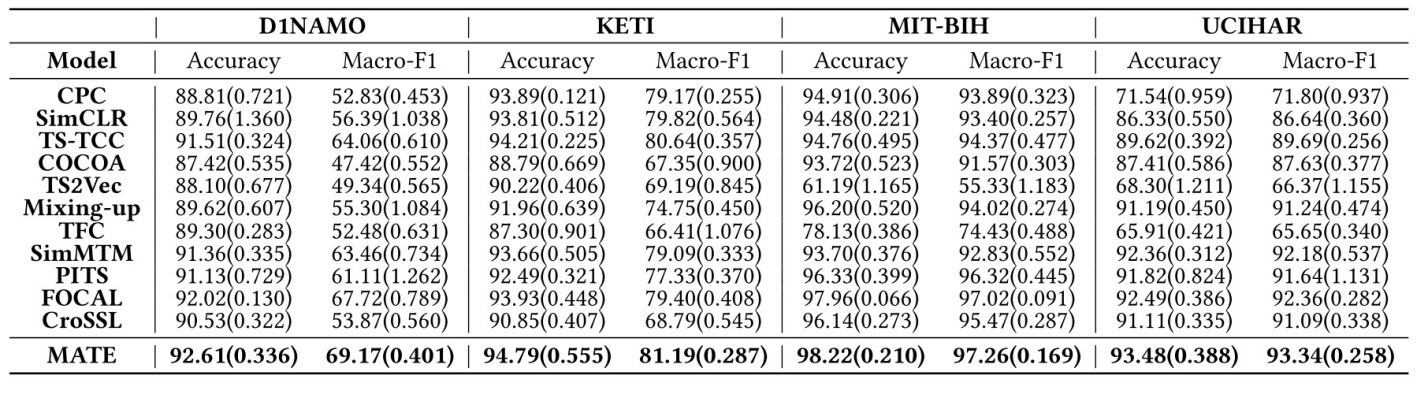
图 7 多模态时间解纠缠模型框架在聚类的结果
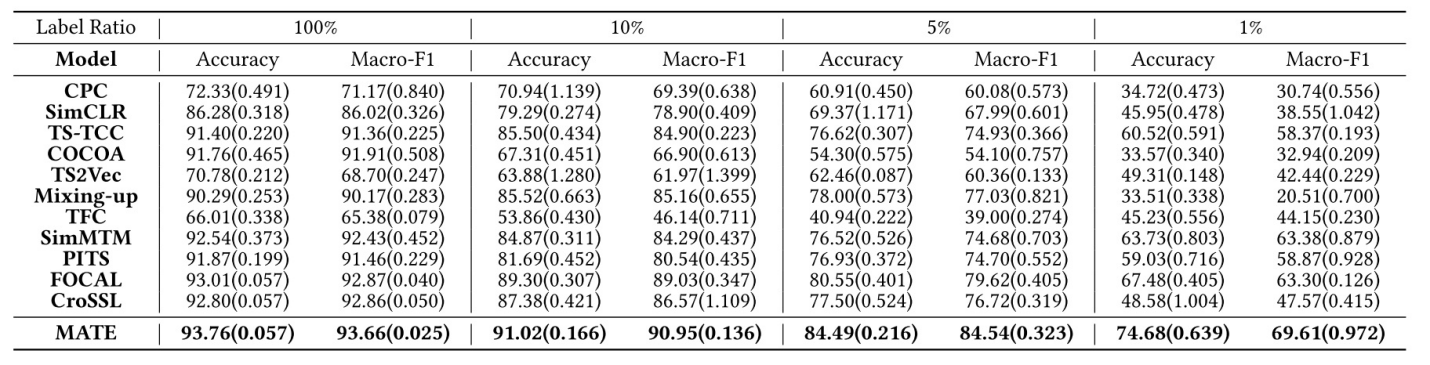
图8 多模态时间解纠缠模型框架在UCIHAR数据集上的自监督结果
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室