导语:
近日,广东工业大学计算机学院数据挖掘与信息检索(DMIR)实验室的论文Disentangling Long-Short Term State Under Unknown Interventions for Online Time Series Forecasting 被CCF-A类会议 AAAI 2025 (Association for the Advancement of Artificial Intelligence )接收。AAAI 是人工智能领域的顶级会议之一。下面带来该论文的详细解读。

1 研究背景
时间序列预测是时间序列分析的基础任务,在金融、交通等领域起到关键作用。然而,在实际的行业应用场景中,时间序列数据具有独特的性质,通常是按顺序依次到达,并非一次性全部获取,而且其分布可能随时间不断发生变化。这就导致在传统场景下依赖小批量训练范式的现有预测方法,难以适应数据分布的动态变化。例如,在金融市场中,新的经济政策、突发事件等因素会使金融数据的分布发生显著改变,而传统方法无法及时有效地捕捉这些变化,进而导致在在线预测场景下,预测结果往往达不到预期,无法满足实际需求。
为了应对在线时间序列预测的挑战,近年来研究人员提出了一系列方法,致力于通过两个关键步骤来解决在线时间序列预测问题:一是将长期和短期状态进行有效分离,二是对短期状态进行合理适应,并重新利用长期状态进行精准预测。然而,尽管这些方法在更新短期状态、组合长期和短期状态等方面取得了一定的效果,但都存在一个共同的潜在问题。它们在设计过程中,都隐含地假定长期和短期状态已经能够从非平稳的时间序列数据中完美地分离出来。但在实际的复杂应用场景中,这一假设很难真正成立。
通过对上述问题的深入分析,本文观察到,时间序列数据的非平稳性主要是由对短期状态的未知干预所引发的。例如,在金融市场中,政策的突然变动、重大突发事件的发生等,都会对短期状态产生未知干预,进而导致数据的非平稳性。因此,为了更有效地解决在线时间序列预测任务,关键在于从受未知干预的时间序列数据中准确地分离出长期和短期状态。基于这一深刻认识,文章提出了一种通用的框架。在理论层面,通过深入研究,建立了相应的可识别理论,为长期和短期状态的分离提供了坚实的理论基础;在实践层面,进一步开发了长短期分离模型(LSTD)。该模型在多个真实世界的在线时间序列预测数据集上进行了实验验证,性能超越了现有的先进方法,充分展示了其在实际应用中的有效性和优越性。
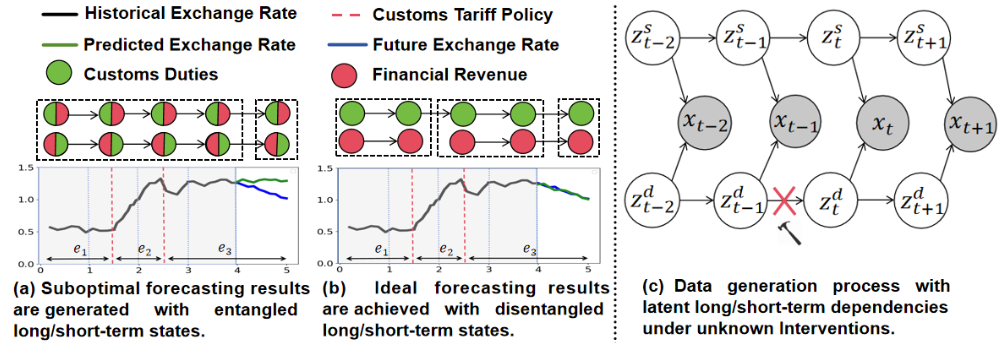
图 1 在线时序数据生成过程
2 在线时序预测(LSTD)
本文在假设 A1(平滑、正且条件独立密度)、A2(非奇异雅可比矩阵)、A3(线性独立)成立的情况下,提出block- wise 识别理论。在短期隐变量间转移边数量最少时,长短期潜在变量是block- wise可识别的,从而保证长短期隐变量正确解耦。

图2 可识别性假设
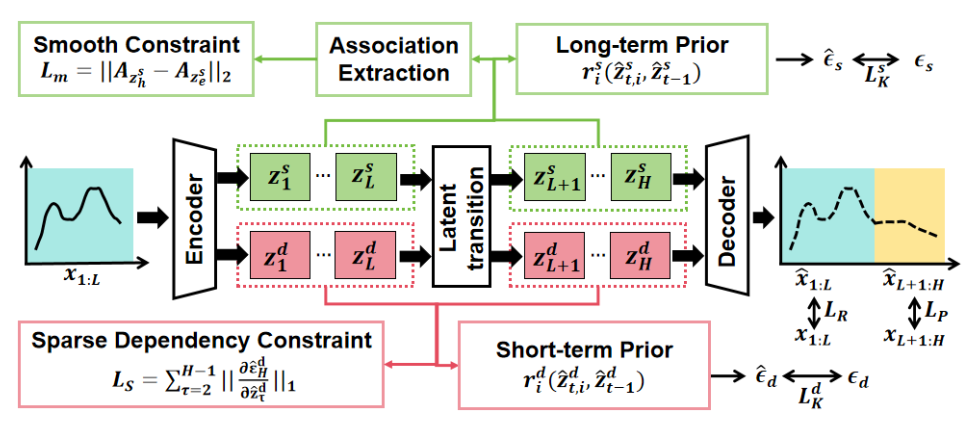
通过可识别理论确定先验网络设计后,本文再根据基于数据生成过程的证据下界(ELBO)确定模型的自动编码器:
其中
和
分别是重构误差和预测误差:
在长期和短期预测模块中,我们分别引入平滑约束保持长期潜在变量的长期依赖和中断依赖约束保证短期影响的中断和遗忘:
平滑约束:
其中,
3 实验结果
在线时序预测模型(LSTD)框架在多个真实数据集,如ECL,Exchange优于最先进的推荐方法,MSE指标提升5%到44%,证明了所提出方法的有效性。
表1 在线时序预测模型在不同数据集上的均方误差(MSE)结果。TCN 缩写为T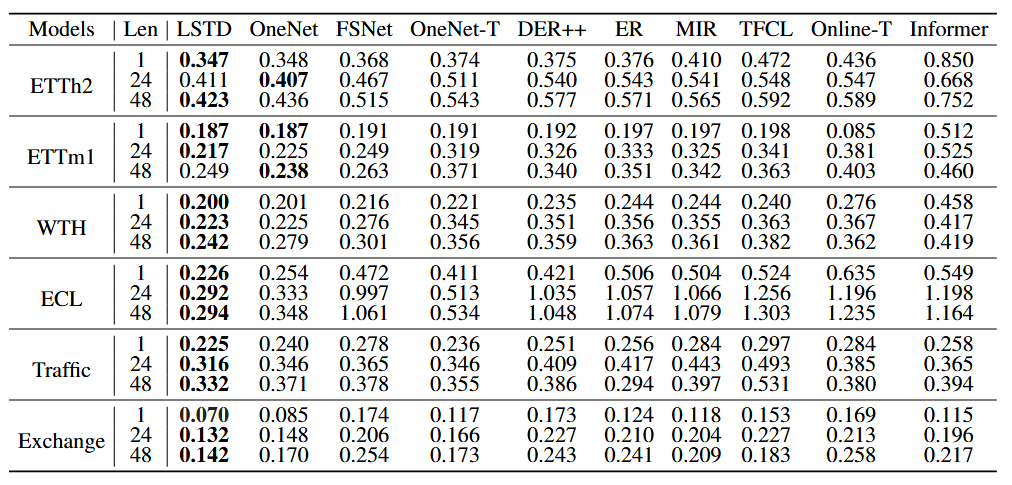
表2 在线时序预测模型在不同数据集上的均方误差(MAE)结果。TCN 缩写为T
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室