近日,广东工业大学计算机学院数据挖掘与信息检索(DMIR)实验室的论文Feature Attribution with Necessity and Sufficiency via Dual-stage Perturbation Test for Causal Explanation被人工智能、机器学习领域的顶级国际会议International Conference on Machine Learning (ICML) 接收。ICML是国际机器学习学会主办的国际会议,也是CCF A 类会议。下面带来该论文的详细解读。
1 研究背景

特征归因是一种通过为输入特征分配权重来解释机器学习模型的方法,其中权重的绝对值表示它们对模型预测的贡献。从数学上说,假设我们有一个函数f,它表示一个训练好的机器学习模型,一个要解释的目标输入
,以及一个基线
其中
是特征
在被认为缺失时的近似值。输入
的预测相对于
的归因是一个向量
,其中
是
对预测
的贡献。标准特征归因方法通过扰动测试来衡量每个特征的贡献,即比较不同扰动下(即输入X的一个子集被设置为其基线值)或扰动前后的预测差异。
然而,当扰动后不同特征的预测变化相似时,这种扰动测试可能无法准确区分不同特征对预测的贡献。我们的关键发现是,导致不同特征在被扰动后预测变化相同的原因可能是不同的。基于这一关键观察,我们扩展了特征归因,以比较每个特征在因果关系概率——充分必要性概率PNS方面的差异。
基于上述对PNS和特征归因之间关系的理解,我们开发了一种新颖的充分必要特征归因方法FANS,以计算反事实概率PNS。具体而言,我们通过提出一个结构因果模型来概括特征归因中扰动测试的一般理解。为了量化作为反事实概率的PNS,我们提出了一种新的双阶段扰动测试来实现反事实推理范式。第一阶段是根据事实扰动的条件分布生成样本,并预测反事实问题。第二阶段涉及扰动每个样本的、不同于其事实扰动的特征子集,然后更新预测。技术上,我们实现了一个双阶段扰动测试。该测试由充分性模块和必要性模块组成。最后,PNS可以通过计算这两个模块的输出的加权和来估计。然而,第一阶段的条件分布可能很复杂,因此我们建议对观测到的输入使用重要性重采样来近似它。大量的实验研究表明,我们的FANS在六个图像和图数据基准上优于现有的特征归因方法。
2 充分必要特征归因(FANS)方法研究
FANS的框架如图1所示。我们首先开发了一种新的双阶段(事实阶段和干预阶段)扰动测试,这个测试由充分性模块和必要性模块组成,最后将这些模块的输出组合在一起,得出PNS。具体而言,通过采用反事实范式,充分性模块和必要性模块的输出PS和PN的计算方式如下:
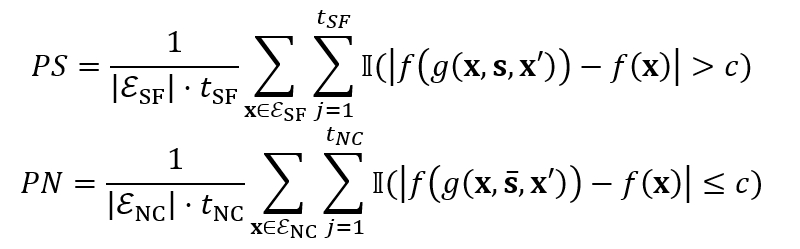
其中,反事实样本的集合E_SF和E_NC难以从事实分布中直接抽取,于是我们采用重要性重抽样的来生成这些样本,其中样本权重公式如下:
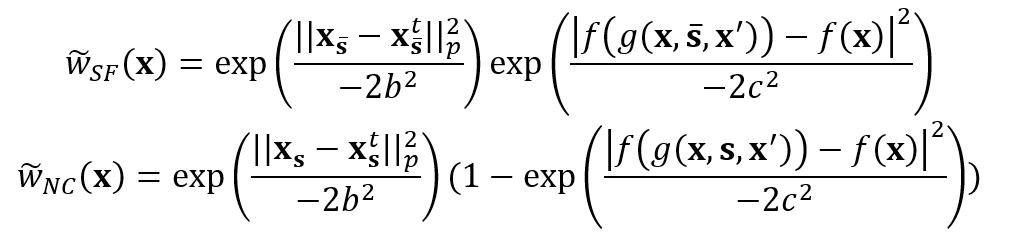
图 1 充分必要特征归因框架
3 实验结果
充分必要特征归因模型(FANS)在三个图像数据集MNIST,Fashion-MNIST,CIFAR10和三个图数据集BACommunity,Citeseer,Pubmed上优于最先进的特征归因方法,证明了所提出方法的有效性。
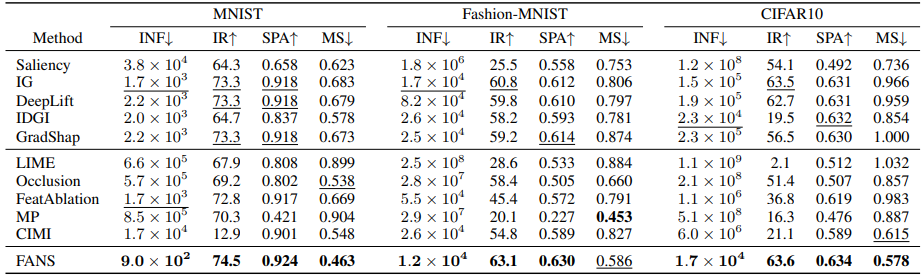
图 2 充分必要特征归因模型在图像数据集上的结果
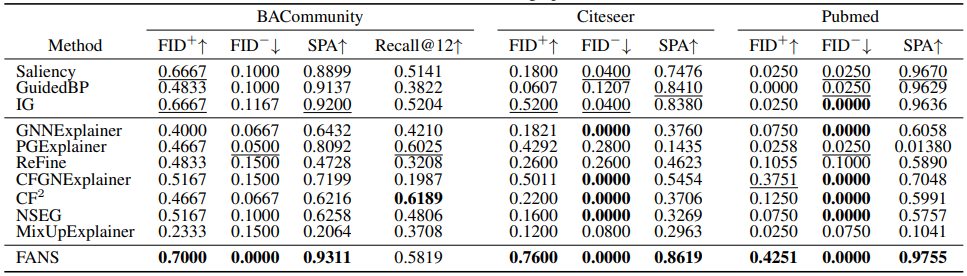
图 3 充分必要特征归因模型在图数据集上的结果
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室