导语:
近日,广东工业大学计算机学院数据挖掘与信息检索(DMIR)实验室的论文 Where and How to Attack? A Causality-Inspired Recipe for Generating Counterfactual Adversarial Examples 被 CCF A类会议 AAAI 2024 (Association for the Advancement of Artificial Intelligence ) 接收。AAAI 是人工智能领域的顶级会议之一。下面带来该论文的详细解读。
深度神经网络(DNNs)在各种任务中取得了巨大的成功,并已广泛应用于面部识别、医学诊断和自动驾驶等关键领域。尽管取得了前所未有的成就,DNNs 仍然容易受到精心设计的对抗样本的攻击。最近,人们致力于通过例如 Lp-norm 限制攻击和无限制攻击生成对抗样本。大多数方法假设攻击者可以任意扰动任意特征,这在现实世界中生成对抗样本时是不合理的,例如,访问图像识别模型的像素输入的受限,将使得这些方法在扰动原始像素空间时失败。此外,仅改变可改变的特征而保持其他特征不变也可能是不切实际的,因为它忽略了由改变特征引起的影响,这一点被大多数现有方法所忽略。举一个启发性的例子,考虑一个金融机构用于评估贷款申请人信用价值的信用评分模型。该模型包含各种特征,如收入、债务、债务收入比和信用历史。在生成对抗样本时,扰动收入而保持债务收入比不变是不合理的,因为债务收入比是由收入和债务决定的。因此,因果生成过程在生成对抗样本的过程中也应该受到考虑。
本文通过考虑因果生成过程,为对抗攻击提供了新的视角,并提出了算法CADE(Counterfactual ADversarial Examples),生成反事实对抗样本。本文通过回答两个基本问题来介绍 CADE: 1)何处攻击:从因果的角度理解对抗样本,以选择有效的扰动变量; 2)如何攻击:利用因果生成过程生成更加真实及合理的对抗样本,因为简单地改变原因变量而不改变效应变量会导致生成不真实的对抗样本。首先,为了回答何处攻击的问题,结合数据的因果生成过程,本文理论分析了判别式DNN的脆弱性,即对干预数据的非鲁棒性,而人类则是由于拥有因果推断的能力而对该类数据鲁棒。例如,如图3左侧所示的数据生成过程,“汽车”始终在“路面”上,人类可以识别“汽车”,即使它在“太空”中(干预数据)。然而,DNN 则将其判别为“卫星”,因为其利用了“太空”这个背景进行决策。根据这种脆弱性,本文明确分析了不同干预对于攻击的效果,为显变量和隐变量的攻击提供了清晰的指导。其次,为了回答如何攻击的问题,关键问题是在给定当前观测时预测变量被干预的效应,所得到的样本也被称为反事实样本。例如,在图3中,给定观测样本(左侧),当对背景进行干预时,干预的后果是图像发生变化(背景从“路面”变为“太空”),而当前观测的其他特征保持不变(颜色,形状),其中保留的部分由外生变量决定,用来表示样本的当前状态。为了生成反事实样本,本文使用了反事实生成框架 (Pearl 2009),该框架需要结合因果生成过程。得益于因果发现、生成模型和因果表示学习取得的成功,恢复数据生成过程并从干预分布中生成反事实样本是可行的。通过了解何处攻击以及如何攻击,本文提出了 CADE 以生成生成反事实对抗样本。在实验方面,本文提出的 CADE 在白盒和基于迁移的黑盒攻击中取得了竞争性结果,并且在没有代理模型的场景下随机干预时也实现了非平凡的性能。
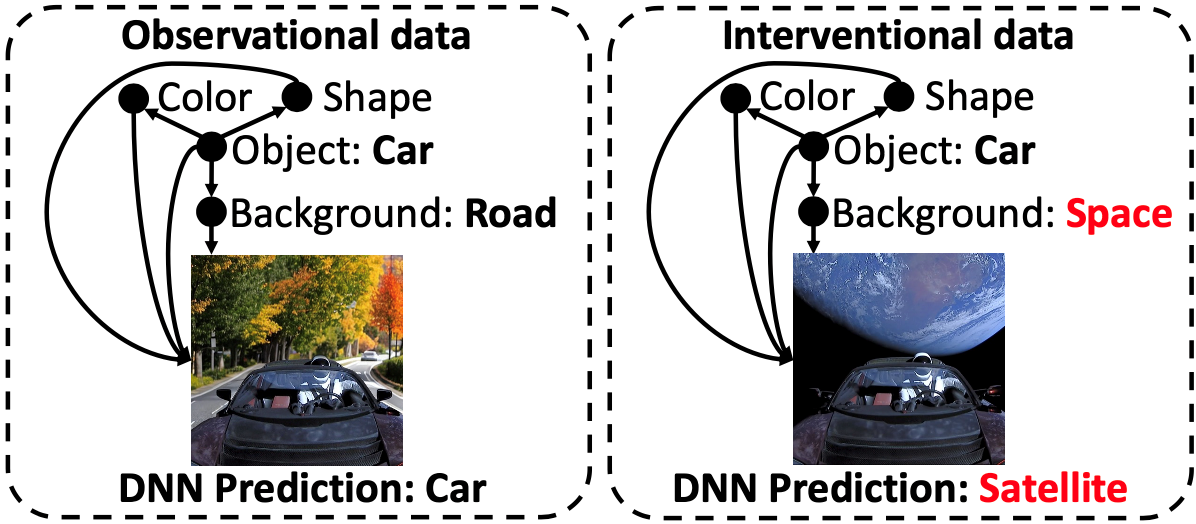
图 1 判别式 DNN 对干预数据的脆弱性
2 何处以及如何攻击
本文通过因果视角重新看待对抗样本,理论分析了对抗样本的存在性回答何处攻击,同时通过考虑在样本当前状态下干预的后果,提出了反事实对抗样本生成算法 CADE,以回答如何攻击。
何处攻击 我们分析了显变量和隐变量的干预。对于显变量:

由于DNN学习的分布
近似
,它在泛化到偏移的干预分布
上的能力有限。这种泛化能力的不足清楚地回答了攻击何处的问题,即,生成从偏移干预分布中得到的且一个保留相同目标
的对抗样本。这可以通过诸如孩子子节点干预,或者同时干预孩子节点和共同父节点来实现。
对于隐变量,面对图像数据时,大多数现有方法在原始像素空间中进行攻击生成对抗样本,然而这在现实世界中是不切实际且成本高昂的。为了缓解这个问题并保持生成的对抗样本的真实性,可以攻击决定图像
的含有语义的隐变量
,其中
的每个变量之间都可能存在因果关系,并且目标变量
包含在确定
的
中:

在大多数情况下,
可以导致
(详见附录证明与分析)。由于DNN只估计
,可以从偏移的
分布中生成对抗样本。由于联合分布可以分解为,因此通过引起
结构变化的干预得到的新机制
可以导致偏移的
。为了使得目标
保持一致,对
及其父节点进行的干预不符合本文考虑的攻击,一些可能的选择可以是除了这两个变量之外改变
结构的变量,例如
的孩子节点。
如何攻击 了解何处攻击之后,下一步是通过考虑在当前状态下的干预的后果来生成对抗样本,因为对一个变量进行干预必然会导致其后代发生变化。可以采用反事实框架(溯因 (Abduction)、作用 (Action) 和预测 (Prediction))生成反事实样本:
溯因(Abduction):推理步骤旨在通过恢复外生变量
来维持给定观测的当前状态的特征:
作用(Action)(干预)和预测(Prediction):在所需的变量
上进行干预,以获得
,其中
是根据图3所示的变量选择(Variable Selection)过程获得的,
表示包含
改变的完整输入。然后,预测每次干预的后果,以获得相应的对抗样本
:
其中,
是一个二值掩码,其中
表示对变量
进行了干预,
表示对变量
并未进行干预。
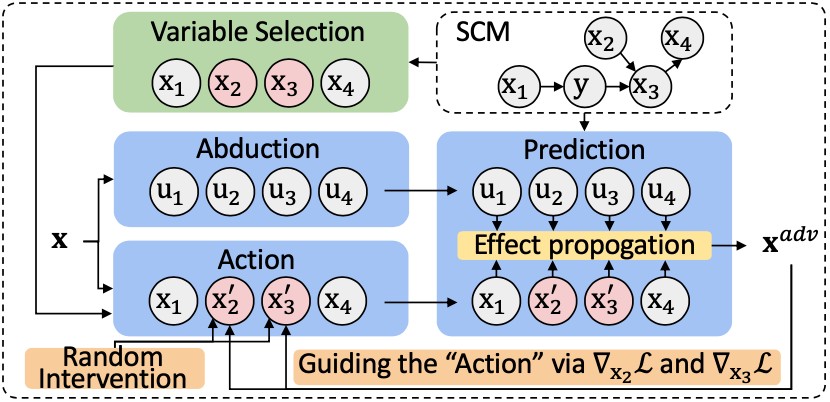
图 3 反事实对抗样本(CADE)模型框架
反事实对抗样本模型(CADE)框架在两个数据集Pendulum和CelebA优于最先进的基线方法,证明了所提出方法的有效性。该成果发表于CCF A区会议AAAI Conference on Artificial Intelligence。
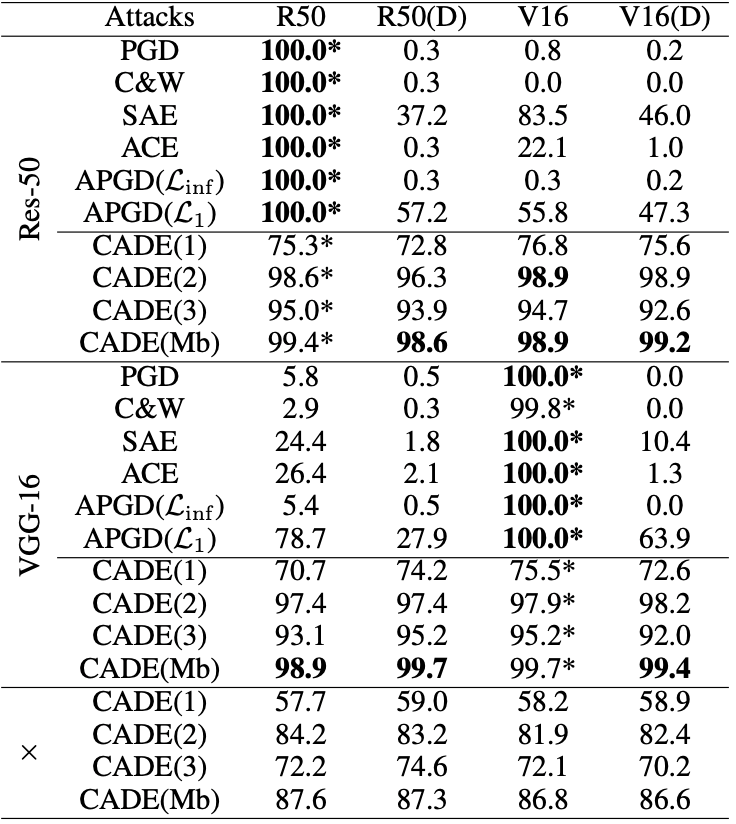
图 4 在 Pendulum 数据集上针对 Res-50 生成的对抗样本可视化。黑色虚线表示原始投影轨迹,红色虚线表示干预后的投影轨迹

图 5 在 Pendulum 数据集上针对 Res-50 生成的对抗样本可视化。黑色虚线表示原始投影轨迹,红色虚线表示干预后的投影轨迹
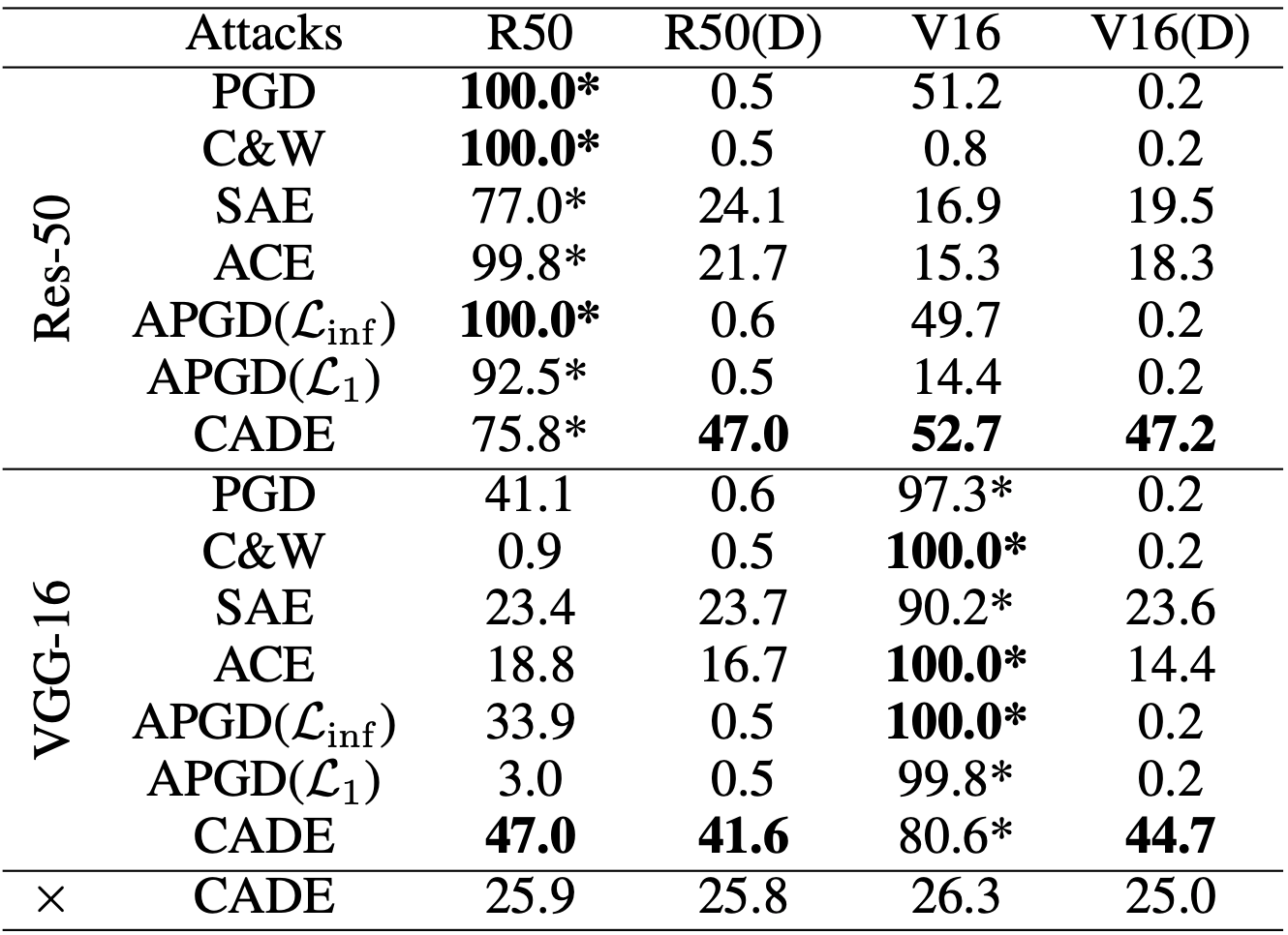
图 6在CelebA数据集上的攻击成功率(ASR)(%),*号表示白盒攻击结果,×表示没有代理模型的攻击结果

图 7在 CelebA 数据集上针对 Res-50 生成的对抗样本可视化
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室