近日,广东工业大学计算机学院数据挖掘与信息检索(DMIR)实验室的论文 Generalization bound for estimating causal effects from observational network data 被32nd ACM International Conference on Information and Knowledge Management (CIKM)接收。CIKM是信息检索和数据挖掘等领域的国际顶级会议,也是CCF推荐B类期刊。下面带来该论文的详细解读。
因果推断中的大部分观察性研究都假设个体之间相互独立。然而,在许多现实场景中,个体之间通过社交网络相互连接,治疗效果可能会从单个体扩散到网络中的其他个体。因此,在流行病学、计量经济学和广告营销等许多领域,人们对根据观测网络数据估计因果效应越来越感兴趣。针对解决从观测网络数据估计因果效应的问题,我们推导了观测网络数据中异质效应估计精度的泛化界。具体地,我们联合基于联合倾向得分的重加权和基于积分概率度量的表征学习这两种范式来推导该泛化界,并提供了重加权和表征学习这两种不同的视角来看待该泛化界。通过对泛化界的分析,我们提出了基于联合倾向得分的加权回归并利用表征学习进行增强的模型。
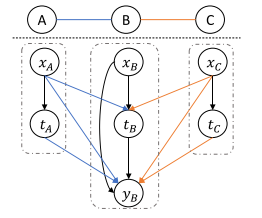
如图1所示,我们以在某三个体组成的小群体中开展工作培训计划为例来描述观测网络数据中个体A和C是如何影响个体B的。令x,t,y分别表示个体的特征(例如专业技能熟练程度)、治疗策略(例如接受职业培训计划)和观察到结果(例如求职情况)。首先,由于网络干扰,单个体的治疗策略会影响其他个体的结果,如
和
所示,即个体B的求职情况也受到其伙伴A,C是否接受就业培训的影响;其次,社交网络的存在带来了新的混淆因子,如
和
所示,即如果个体B的伙伴A,C具备扎实的专业技能,个体B就更有可能因朋辈压力而接受就业培训,而伙伴A,C带来的竞争压力也会影响个体B的求职情况。
泛化界的推导及网络设计
我们联合基于联合倾向得分的重加权和基于积分概率度量的表征学习这两种范式来推导泛化界,结果如下式所示:
我们可以从重加权视角来看待上述泛化界,即引入表征学习是为了修正平衡权重的估计误差。当平衡权重无法被准确估计时,网络数据中的混杂偏差将不会被完全消除,这意味着重加权后的特征和治疗对之间存在相关性,而这刚好能够被IPM项所捕获。因此,我们可以通过最小化IPM来进一步消除剩余的混杂偏差,其通过学习平衡表征来实现。
与此同时,我们发现从表征学习的角度来看,重加权技术也可以增强表征学习,如下式所示,我们发现与纯粹的表征学习相比,引入平衡权重可以得到更紧的泛化界。
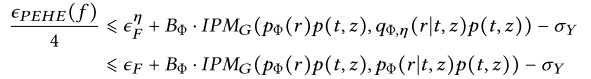
将
这两种观点
统一起来,我们知
道在
网络场景中,重加权和表征学习结合可以相互增强。
基于此,我们设计了如图2所示的网络结构。
实验结果
本研究在两份半生成数据的实验中证明了模型的有效性(图3和表格1、2所示)和理论的正确性(图4所示),该成果发表于CCF B类会议 CIKM2023 上。
图3 在BC和Flickr数据集上反事实估计的估计误差
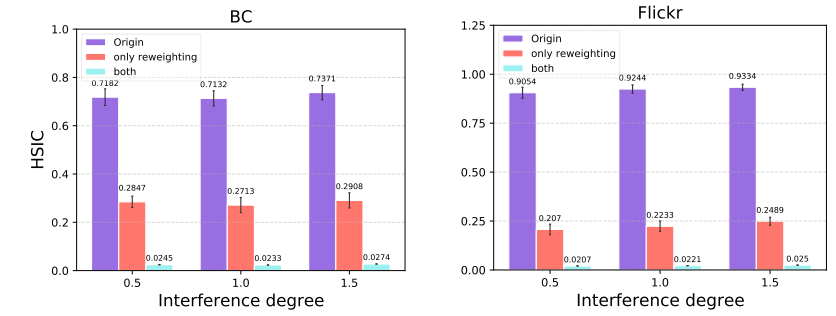
图4 理论正确性验证:表征学习能修正重加权的估计误差
表2 在Flickr数据集上异质效应估计精度的估计误差
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室