近日,广东工业大学计算机学院数据挖掘与信息检索实验室(DMIR)团队的论文Some General Identification Results for Linear Latent Hierarchical Causal Structure(线性隐变量层级结构的识别性)被人工智能领域的国际顶级学术会议International Joint Conference on Artificial Intelligence(IJCAI)-23接收。国际人工智能联合会议(IJCAI)是人工智能领域中最主要的学术会议之一,第32届会议将于8月19日至8月25日在中国澳门举行。下面带来该论文的详细解读。

论文名称:Some General Identification Results for Linear Latent Hierarchical Causal Structure
论文作者:Zhengming Chen, Feng Xie, Jie Oiao, Zhifeng Hao, Ruichu Cai*
转载须标注出处:DMIR实验室
研究动机
线性隐变量层级模型(LHM)常用来建模隐变量(未观测变量)的因果结构。LHM 的核心思想是将多个隐变量按照层级结构组织起来,每个变量都受到上一层变量的影响,且只有叶子节点是观测变量。这使得模型能够捕捉观测变量的更高层次的特征,并且可以应用于各种领域,如语音识别、图像处理和自然语言处理等。
本文研究了在更一般的条件下线性隐变量层级结构(LHM)学习的问题。与现有工作的不同在于本文研究的结构不限于树结构的图,没有“非三角形”结构的约束,而且允许数据是部分高斯。我们表明,通过使用二阶统计量,可以识别到隐变量的马尔科夫等价类。此外,隐变量间的方向可以通过部分非高斯数据确定。基于上述理论结果,实验室博士生陈正鸣在郝志峰老师、蔡瑞初老师的指导下,设计了一个有效的算法来学习线性隐变量层级结构。
研究方法
本文放宽了树结构图,没有“三角形”结构,和噪声分布是非高斯的约束,在更一般的条件下研究线性隐变量层级结构学习的问题。我们基于线性隐变量模型的假设,将LHM的识别性问题分成两个子问题:不可约条件下的因果骨架的可识别性、分布条件下的因果方向的可识别性。
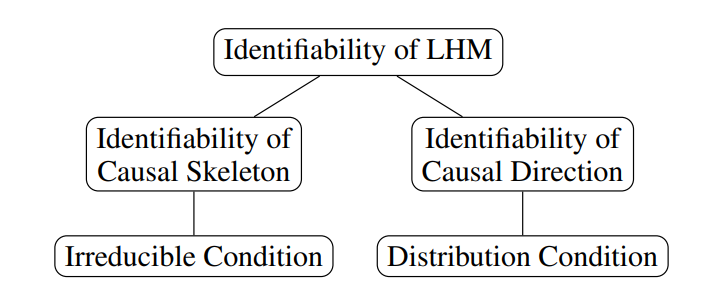
图1:线性潜在层次结构的可识别性
不可约条件,是一种广义的“纯”假设,其定义每个隐变量至少有3个”纯“的子变量集,并且除了这三个子变量集,该隐变量至少还有一个邻接节点。(该条件放宽了现有方法的“非三角形”结构约束)
分布条件,即满足(1)两个隐变量之间至少有一个是非高斯噪声,或者(2)两个隐变量中至少有一个不能被这两个隐变量的共同原因d分离的非高斯祖先变量。(该条件放宽了现有非高斯假设的约束)
因果骨架的可识别性建立在不可约条件上。本文在不可约条件下,通过研究Tetrad约束在层级结构下的“图准则”,可以识别因果聚类;进而给出了识别纯与非纯聚类的定理、不同聚类的融合定理,以引入的隐变量。基于线性模型的传递性,本文提出了一种从下至上的重构隐变量层级结构骨架的算法(算法1中的Step I)。
因果方向的可识别性是建立在分布条件上。不可约条件只能识别到马尔可夫等价类。为了进一步识别马尔可夫等价类中的无向边的因果方向,我们发现数据的部分非高斯性(即分布条件)可以识别隐变量的因果方向。我们表明,在分布条件下,使用部分数据的非高斯性,可以通过GIN约束识别隐变量间的因果方向(算法1中的Step II)。通过以上分析,我们给出了识别线性层级结构模型的算法:

该算法主要有两个步骤:
Step I:识别因果骨架
step1.1:识别因果聚类。在不可约条件下,使用Tetrad约束识别因果聚类;
step1.2:引入没有重复的隐变量。包括合并有共同隐变量的聚类,识别已引入隐变量的聚类等;
step1.3:更新因果骨架。基于线性的传递性,更新隐变量的值为其可观测后代。
Step II:识别因果方向
在分布条件下,使用GIN约束识别因果方向。
一个简单的示例如下所示。其中X代表观测变量,L代表隐变量。圆圈代表隐变量的噪声服从高斯分布,方块代表隐变量的噪声服从非高斯分布。
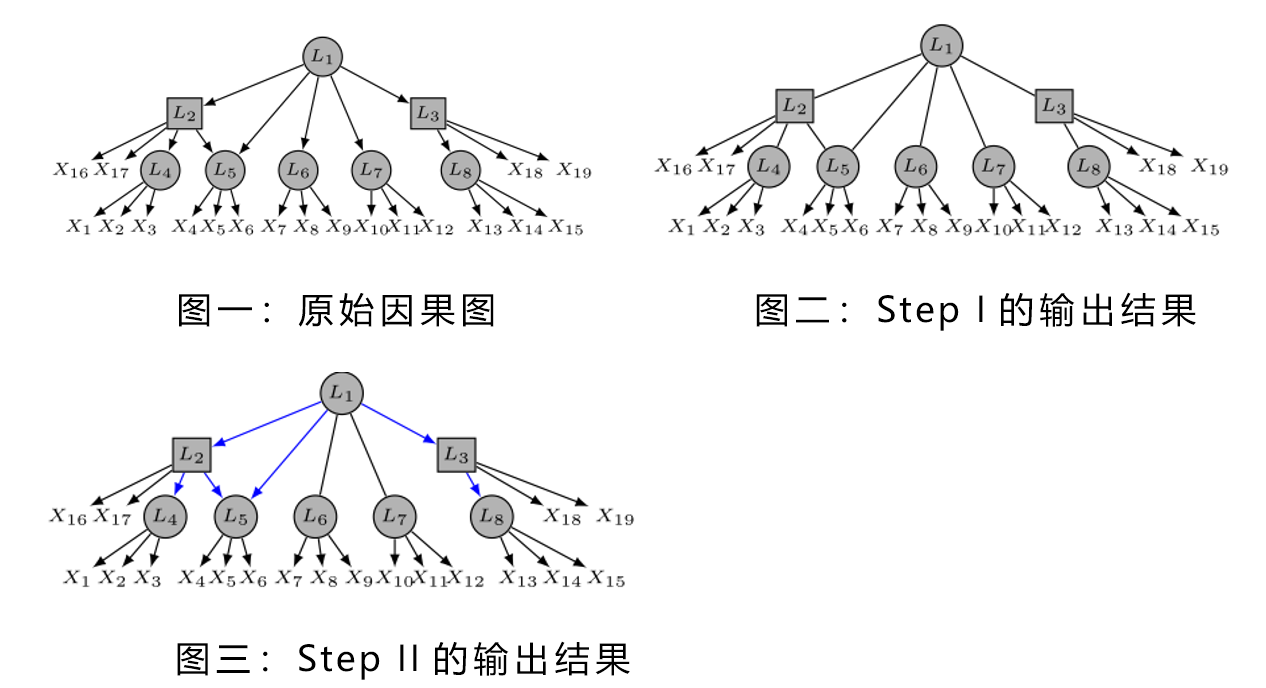
进一步的,基于所提出的识别性算法,我们给出了线性隐变量层级结构在更加一般条件下的识别性。

实验
我们在仿真数据上验证我们算法关于不同样本量、不同线性隐变量模型(分别有测量模型,隐树模型,隐变量层级结构)下的性能。
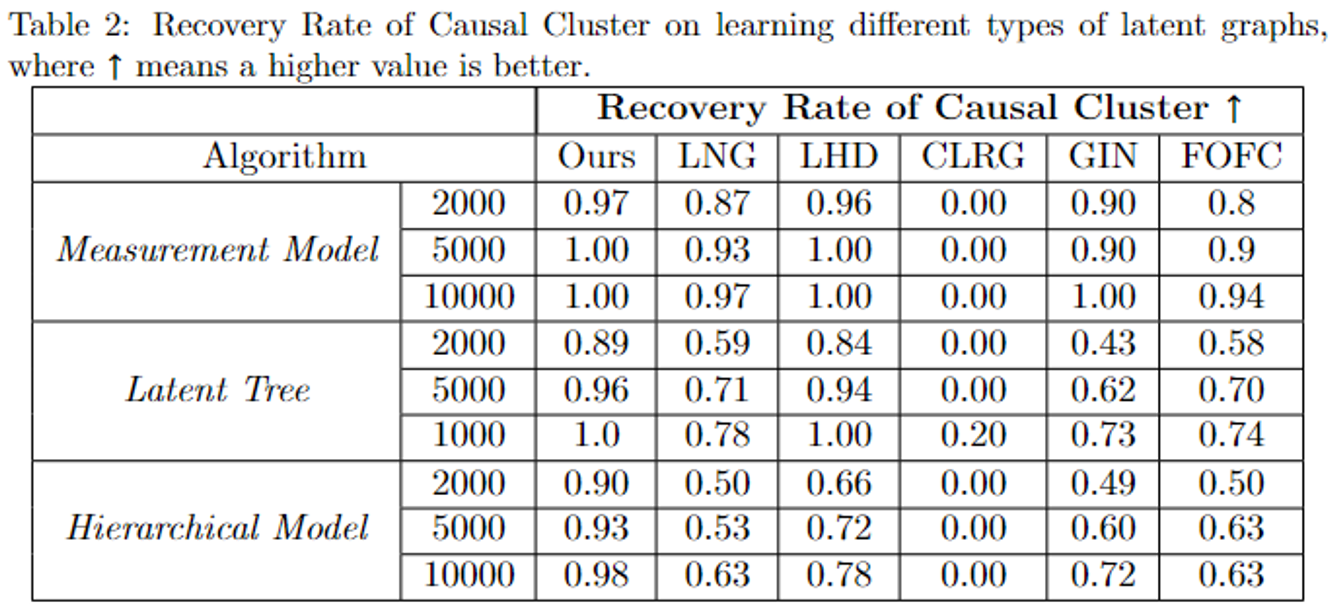
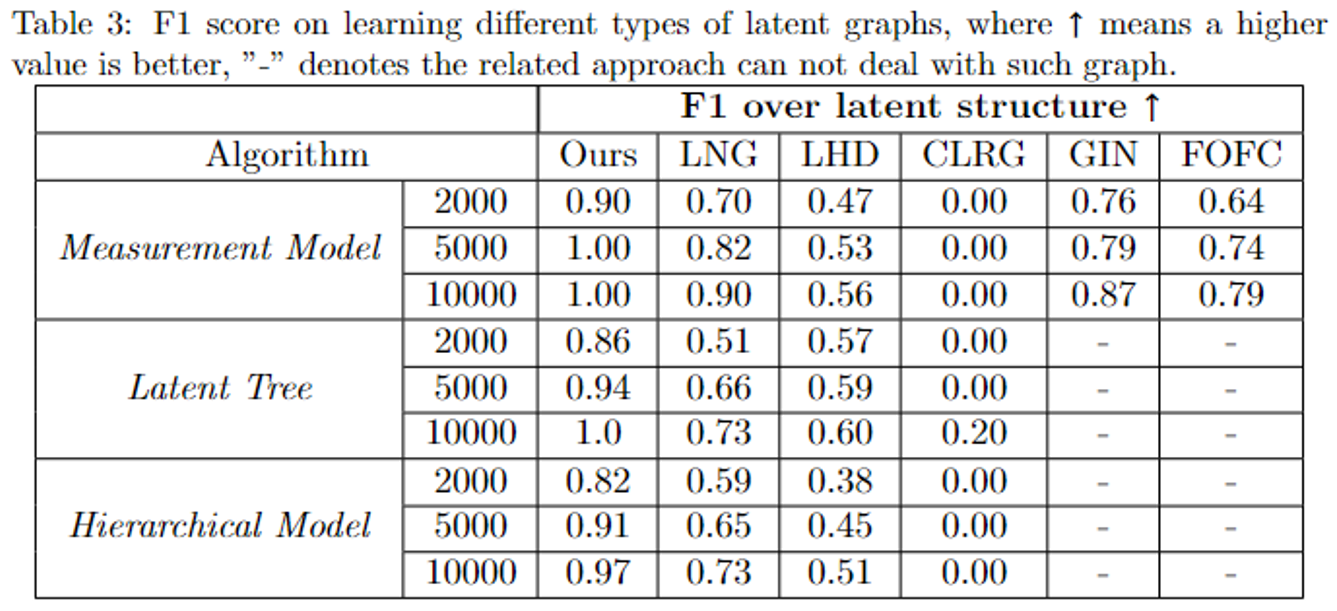
结果显示,相较于其他算法,我们的算法在不同的模型下的表现都最佳。
总结
本文设计了一个有效的算法来学习线性隐变量层级结构(Linear Latent Hierarchical Model,LHM),在更一般的条件下(放宽了树结构图,没有“三角形”结构,和噪声分布是非高斯的约束),即不可约条件下和分布条件,回答了LHM的识别性。我们的理论结果拓展了线性隐变量模型的应用范围,使得这一类模型可以用来解决更加一般场景下的实际问题。
团队简介
广东工业大学DMIR团队成立于2010年,长期致力于数据挖掘基础理论的深度研究,并围绕着数据挖掘理论开展因果关系发现与因果性学习、深度学习等方面的钻研,科研成果广泛应用于虚拟社会行为理解、城市感知数据分析、生物医疗数据挖掘等社会发展的重大方面。
DMIR团队主要成员在上述领域先后主持国家优秀青年基金、科技部”科技创新2030“重大项目、省杰出青年基金、省特支计划等项目;在因果关系发现、因果性学习方面开展了系列有益探索,在ICML、NIPS、AAAI、IJCAI等领域重要会议和TNNLS、TKDE等国际著名期刊发表论文100余篇;协助华为、腾讯、南方电网等企业解决了因果故障定位、因果决策优化、因果个性推荐等应用难题,取得了良好的经济和社会价值。
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室