近日,广东工业大学计算机学院数据挖掘与信息检索(DMIR)实验室的论文Graph Domain Adaptation: A Generative View 被数据挖掘领域的期刊ACM Transactions on Knowledge Discovery from Data(TKDD)接收。TKDD是美国计算机协会(ACM)主办的国际期刊,也是CCF推荐B类期刊。下面带来该论文的详细解读。

针对图像数据、文本数据、文本数据和时间序列数据,当前已出现大量的无监督域自适应相关工作,而针对图形数据的自适应方法还很少。例如,利用共享图卷积网络和基于生成对抗网络(GAN)的对抗正则化实现了域自适应网络嵌入。利用注意机制整合全局和局部一致性,借助梯度反转层(GRL)欺骗域识别器,提取跨域节点嵌入。综上所述,这些对抗性方法一般作用于传统数据类型的领域自适应任务,而作用于图形数据的方法很少,导致图结构化数据的属性没有得到明确利用。
与传统数据不同的是,图形数据具有生成过程不确定性高、特定领域结构复杂度高等特点。我们以下图(a)中的社交网络为例。所观察到的社交网络不仅受到潜在语义因素(如节点之间的共同兴趣)的控制,而且还受到特定领域的社区(如由特定领域的网络策略引起的)和不确定性(如两个兴趣相同的节点可能不认识彼此或者社交网络中的僵尸粉丝)的控制。对图结构数据的这些重要特性的忽视妨碍了图域自适应模型的性能。
学习一个健壮的图表示法,需要包含两种重要的信息。首先是域不变的结构/拓扑信息,其次是域不变的节点信息。然而,同时提取这些域不变信息并非易事。从观测到的图结构数据中提取域不变结构信息的主要困难是不确定性。由于观测图数据的高度不确定性,即使对于被同一社区包围的用户,不同平台/域之间的观测图结构完全不同,例如,图1 (a)和(c)中给出的情况。而从不同的平台/域中提取不同社区的域不变节点信息的主要障碍通常是由域指定的网络策略引起的。
给出一个如图1中(a)和(b)所示的详细示例,具有相似观察图结构的用户可以被不同的社会群体所包围。在这种情况下,由于社区的分布和类型在不同的域之间有所不同,仅仅利用梯度反转层和 MMD 等传统的域自适应限制很难提取出域不变的节点表示。
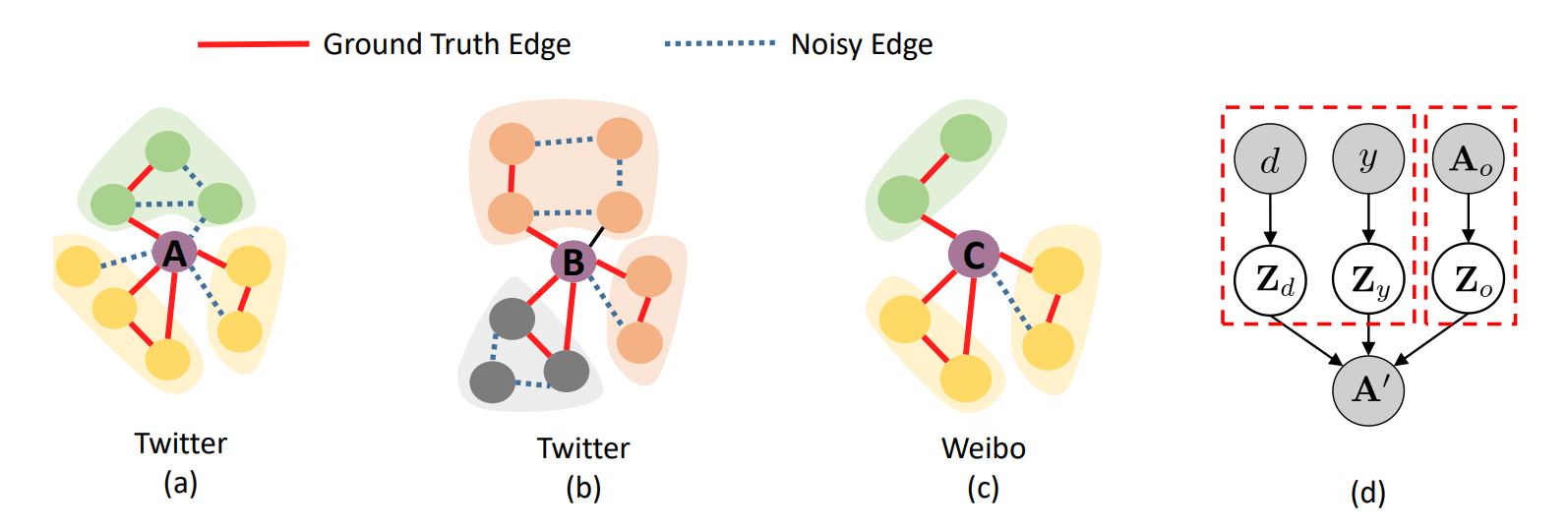
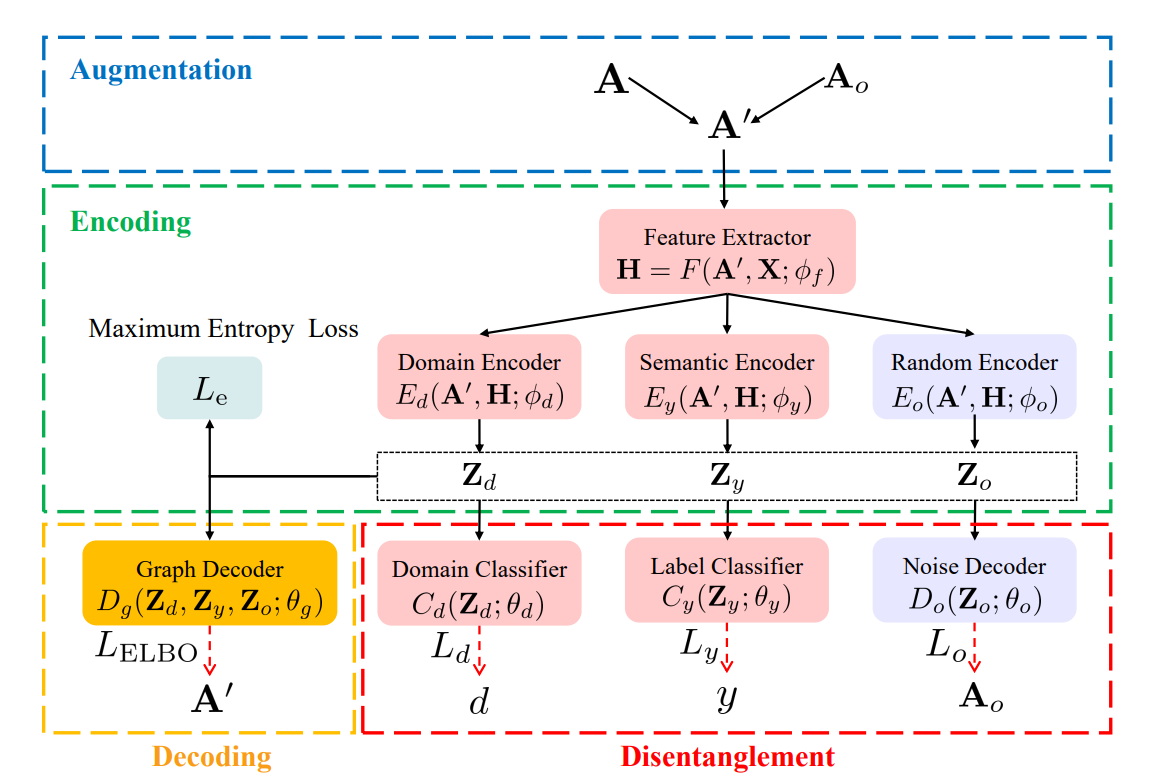
因此,我们提出了一个基于分离的图域适应模型(简称 DGDA),它是由图1(d)所示的图数据生成过程驱动的。
具体地说,我们假设图形数据的生成过程是由三种独立的潜变量控制的,即语义潜变量
、领域潜变量
和随机潜变量
。这三组潜在变量分别由语义信息
、域信息
和不确定度
编码。通过对这三个潜变量的重构和分离,可以方便地对基于
的不同图的标号进行分类。技术上,我们使用变分图形自动编码器来重建这些潜在的变量。本文采用标签分类器和领域分类器对语义潜变量和领域潜变量进行了分类。通过重构图形数据的不确定性,进一步解决了随机潜变量的问题。此外,我们将潜变量正则化应用于这三类潜变量,以获得更好的解缠效果。广泛的实验研究表明,针对图形数据,我们的方法优于最先进的无监督领域自适应方法。
在变分模型自动编码器 (VGAE) 的基础上进行改进,进一步将潜在变量
分解为
、
和
。得到边界似然的变分下界:
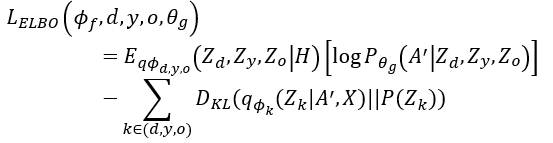
随后我们通过训练领域分类器来提取领域信息,通过使二元交叉熵损失
最小化来学习参数
。最后给出了域解缠模块的目标函数:
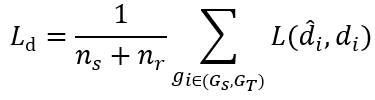
通过在源域上训练标签分类器进行语义变量构建,目标函数如下:
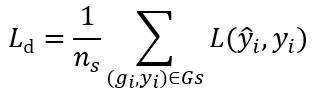
我们给出了噪声变量重构模型
,重构了数据增强引入的噪声信息,即噪声矩阵
,可以这样表述:
为了排除潜在变量中的冗余信息,我们对每个潜在变量采用元素方法的最大熵损失
约束:

通过上述讨论,我们设计出格兰杰因果对齐模型,如图2所示。
图域自适应 (DGDA) 模型在模拟数据以及真实数据性能表现均优于传统的其他方法(如图3、图4所示)。
图 4 图域自适应 (DGDA) 模型效果
 邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室
邮编:510006 地址:广州市番禺区广州大学城广东工业大学工学馆一号馆723室